-
[Keras] 튜토리얼4 - RMSE, R2 (feat.회귀모델)💫 Computer Science/Python & AI Framework 2019. 12. 17. 00:27
● 데이터셋 나누기
회귀모델에서 성능을 평가하는 RMSE와 R2에 대해 알아보기 전에 먼저 train data와 test data를 분류해 보도록 하겠습니다. train데이터와 test데이터를 나누지 않는다면 머신은 정해진 답만 외우는 형식으로 훈련을 하게 될 것이고 새로운 데이터가 들어왔을때 전혀 예측을 하지 못하게 됩니다.
Train Data = 모델의 훈련을 위한 훈련용 데이터.
Test Data = 모델을 평가하기 위해 정답(결과)을 이미 알고있는 테스트용 데이터.
Validation Data = 여러 분석 모델 중 어떤 모델이 적합한지 선택하기 위한 검증용 데이터.
대체로 훈련데이터 : 테스트데이터의 비율은 7:3 정도를 사용한다고 하고, validation data도 사용하였을 때는 6:2:2를 가장 많이 사용한다고 합니다(Simple Validation). validation data는 주로 데이터가 충분할 때 많이 사용합니다.
● 예제 코드
12345678910111213141516171819202122232425from keras.models import Sequentialfrom keras.layers import Denseimport numpy as npx_train = np.array([1,2,3,4,5,6,7,8,9,10])y_train = np.array([1,2,3,4,5,6,7,8,9,10])x_test = np.array([11,12,13,14,15,16,17,18,19,20])y_test = np.array([11,12,13,14,15,16,17,18,19,20])# 데이터 셋을 train과 test로 분류x_predict = np.array([21,22,23,24,25])model = Sequential()model.add(Dense(10, input_dim=1, activation='relu'))model.add(Dense(5))model.add(Dense(5))model.add(Dense(1))model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])model.fit(x_train, y_train, epochs=200, batch_size=2)loss, acc = model.evaluate(x_test, y_test, batch_size=2)print('acc : ', acc)print('loss : ', loss)y_predict = model.predict(x_predict)print(y_predict)cs - 결과
acc : 1.0
loss : 0.00025769622588995845
[[10.992302]
[11.99061 ]
[12.988922]
[13.987234]
[14.985544]
[15.983853]
[16.982162]
[17.980473]
[18.978785]
[19.977097]]acc값이 1이라는 것은 x_predict와 y_predict값이 100프로 일치했다는 것을 의미합니다.
앞에서 말했듯이 소수점을 사용하는 회귀모델에서는 acc값 대신 정확성을 나타내는 다른 지표를 사용하게 됩니다.
○ RMSE
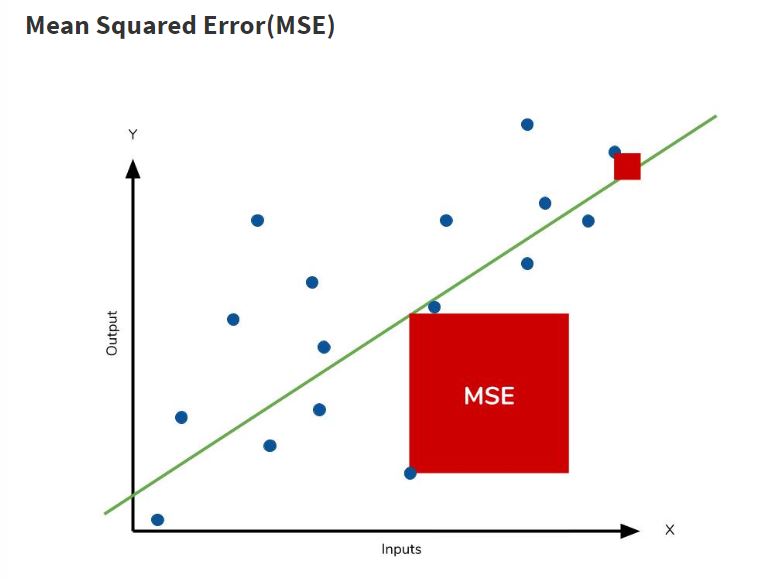
MSE : 예측값과의 거리(오차)를 통해 구함 
RMSE 공식 RMSE는 앞 포스팅에서 설명했던 MSE값에 ROOT만 씌운 값입니다.
(참고 : 2019/12/16 - [SW개발/Python Keras] - [케라스] 무작정 튜토리얼3 - 검증손실 값(acc, loss))
RMSE를 사용하면 오류 지표를 실제 값과 유사한 단위로 다시 변환하여 해석을 쉽게 할 수 있습니다.
회귀문제에서 RMSE가 일반적으로 선호되는 방법이지만, 상황에 맞는 다른 방식을 사용해야 합니다. 특이값이 많은 경우에는 MAE(Mean Absolute Error)를 사용하는 것이 좋다고 합니다.
구현
1234from sklearn.metrics import mean_squared_errordef RMSE(y_test, y_predict):return np.sqrt(mean_squared_error(y_test, y_predict))print('RMSE : ', RMSE(y_test, y_predict))cs ○ R2
R2 값은 회귀 모델에서 예측의 적합도를 0과 1 사이의 값으로 계산한 것입니다. 1은 예측이 완벽한 경우고, 0은 훈련 세트의 출력값인 y_train의 평균으로만 예측하는 모델의 경우입니다.
구현
123from sklearn.metrics import r2_scorer2_y_predict = r2_score(y_test, y_predict)print('R2 : ', r2_y_predict)cs r2_score와 mean_squared_error는 sklearn을 설치하여 임포트 하여 사용하였습니다.
회귀모델의 오류지표는 MSE, RMSE R2 외에도 MAE, MAPE, MPE가 있습니다. (더 알아보기)
'💫 Computer Science > Python & AI Framework' 카테고리의 다른 글
[Keras] 튜토리얼6 - train, test, validation DATA (0) 2019.12.19 [Keras] 튜토리얼5 - summery()로 모델 구조 확인 (1) 2019.12.18 [Keras] 튜토리얼3 - 검증손실 값(acc, loss) (2) 2019.12.16 [Keras] 튜토리얼2 - 하이퍼파라미터 튜닝이란? (0) 2019.12.12 [Keras] 튜토리얼1 - Sequential Model 구현 (2) 2019.12.11