-
[딥러닝] Bias-Variance Tradeoff 와 앙상블✨ AI 2020. 1. 2. 01:19
● Bias-Variance Tradeoff
머신러닝을 이용해 분류기를 만들때, 테스트 하는 과정을 거치며 많은 에러들이 나오게 되는데 이런 에러들을 MSE로 분석해보면 Bias와 Variance의 식으로 정리됩니다.
Learning Error = Bias + Variance

Bias : 학습된 분류기와 실제 값 사이의 제곱 에러, 정확도와 비슷한 개념
Variance : 학습된 분류기들이 각기 다른 학습셋에 성능의 변화정도가 급하게 변하는지 안정적으로 변하는지를 나타내는 척도
○ High Variance & Low Bias
모델이 높은 variance와 낮은 bias를 가질 때, 일부는 정확하게 매핑되지만 많은 데이터가 정확하게 예측하지 못합니다. 모델을 너무 tight하게 학습하여 데이터가 조금만 변해도(ex 노이즈) 모델이 매우 다른 결과를 내놓기 때문입니다.
○ Low Variance & High Bias
모델이 낮은 variance와 높은 bias를 가질때, 모델은 매우 안정적인 결과를 내놓으며 데이터가 달라도 비슷한 구역으로 예측값을 매핑합니다. 하지만 틀린 곳을 매핑한다는 것이 문제입니다. 이는 데이터 변화에는 안정적이지만, 학습을 너무 rough하게 하여 애초에 모델 성능이 좋지 않다는 것입니다.
결론적으로 bias와 variance모두 낮아야 좋은 모델이라고 할 수 있을 것입니다.

○ Under fitting
알고리즘의 Bias가 크다는 것은 모델이 정상적으로 학습을 마친 후 정확도가 기대치보다 떨어지는 것을 의미합니다. 즉, 이상적인 decision boundary에 비해 지나치게 단순한 decision boundary(ex 직선)을 사용한 경우입니다.
○ Over fitting
알고리즘의 Variance가 크다는 것은 정상적으로 학습을 마친 후 새로운 데이터 셋에 대해서는 그 결과가 매우 다르게 나온다는 것을 의미합니다. 즉, 이상적 decision boundary보다 지나치게 복잡한 decision boundary(ex 복잡한 곡선)을 사용한 경우입니다. 즉, 피처가 너무 많거나 지엽적인 데이터를 학습하여 새로운 데이터에 대해 잘 예측을 못하는 것을 의미합니다.
overfitting을 방지하는 3가지 방법
1. training data를 많이 모으는 것이다. 데이터가 많으면 training set, validation set, test set으로 나누어서 진행할 수 있고, 영역별 데이터의 크기도 커지기 때문에 overfitting 확률이 낮아진다. 달리 생각하면 overfitting을 판단하기가 쉬워지기 때문에 정확한 모델을 만들 수 있다고 볼 수도 있다.
2. feature의 갯수를 줄이는 것이다. 이들 문제는 multinomial classification에서도 다뤘었는데, 서로 비중이 다른 feature가 섞여서 weight에 대해 경합을 하면 오히려 좋지 않은 결과가 나왔었다. 그래서, feature 갯수를 줄이는 것이 중요한데, 이 부분은 deep learning에서는 중요하지 않다고 말씀하셨다. deep learning은 sigmoid 대신 LeRU 함수 계열을 사용하는 것도 있고 바로 뒤에 나오는 dropout을 통해 feature를 스스로 줄일 수 있는 방법도 있기 때문에.
3. regularization. 앞에서는 weight이 너무 큰 값을 갖지 못하도록 제한하기 위한 방법으로 설명했다. 이 방법을 사용하면 weight이 커지지 않기 때문에 선이 구부러지는 형태를 피할 수 있다.
(출처)예를 들어 어떤 모델에 대한 결과가 Train-data set에서는 정확도가 80퍼센트, Test-data set에서는 78프로가 나왔으면 이 모델(알고리즘)은 성능은 그다지 좋지 않지만(Bias가 크지만), 새로운 데이터(Unseen Data)가 들어와도 어느정도 성능이 유지되는(Variance가 작은) 모델인 것입니다.

딥러닝 이전 머신러닝에서는 bias와 variance를 동시에 줄이기가 쉽지 않았다고 합니다. 때문에 둘의 trade off를 고려하여 둘을 합하였을 때 최저점을 찾는 것을 목표로 했습니다. 하지만 딥러닝은 비교적 쉽게 bias와 variance를 동시에 줄일 수 있습니다.
위 그림에서 x축은 모델 complexity이고, 즉 오른쪽으로 갈수록 모델은 복잡해지고, 오버피팅의 가능성이 높아지며 bias는 낮아지지만 새로운 데이터에 대해 취약해집니다(variation이 높아진다). 왼쪽으로 갈수록 모델은 단순해지지만 기본데이터조차 제대로 맞추지 못하게 됩니다(bias가 높아진다).
● 앙상블(bagging,boosting)과 bias, variation
2019/12/31 - [분류 전체보기] - [케라스] 무작정 튜토리얼10 - 앙상블(ensemble)
[케라스] 무작정 튜토리얼10 - 앙상블(ensemble)
● 머신러닝에서 앙상블(ensemble)이란? 앙상블 기법은 동일한 학습 알고리즘을 사용해 여러 모델을 학습하는 기법입니다. 괜찮은 Single Learner(단일 학습기)보다 Weak Learner를 결합하면 더 좋은 성능을 얻을..
ebbnflow.tistory.com
- bagging
bagging은 데이터셋을 선별적으로 학습합니다. 하지만 여전히 각각의 모델은 모든 data를 동등하게 대합니다. 때문에 못알아보던 data를 알아보게 되지는 않습니다. 다만 여러개의 모델의 평균을 통해 최종결과를 얻기 때문에 그 결과가 안정적이게 됩니다. bagging은 특히 variance에러를 줄여주는데 효과적입니다. 따라서 분류 클래스의 밸런스가 맞지 않거나 할 때 매우 안정적인 분류 결과를 보여주는 장점을 가지고 있습니다. (막 돌려도 기본 이상을 하는 모델링 방식)
- boosting
boosting에서 각각의 모델은 feature를 동등하게 대하지 않습니다. 못알아보던 feature를 점점 더 중요하게 여기며 가면 갈수록 그것만 공략합니다. 뒷모델은 앞에서 잘알아보는 feature는 고려하지 않습니다. 이미 그 feature를 잘인식하는 model은 앞에 많습니다. 그 feature는 틀리더라도 앞에서 틀린걸 해결하는게 중요하게 됩니다. 때문에 모델의 기본적인 정확도, bias가 개선됩니다. 마찬가지로 여러 모델이 최종결과를 결정하기 때문에 그 결과가 안정적입니다.
boosting은 모형 자체가 가지는 가정과 실제 데이터와의 모순으로 생기는 bias까지 줄여줍니다. varince를 줄이는 방식은 bagging과 유사하게 다수의 모형의 voting(실제는 weighted된)을 통해서 줄이지만, bias는 분류가 어려운 문제를 풀기 위해 지속적으로 weak learner를 만듭니다. 이 때문에 boosting이 outlier나 anomaly detection 문제를 잘 푸는 이유가 됩니다.
오버피팅(과적합)을 줄이기 위한 방법에는 단계별로 대표적인 방법 몇 가지가 있습니다.
- 데이터 전처리 -> 데이터 구성시
- EarlyStopping -> 피팅(훈련)시
- Dropout -> 모델 구성시
위 세 단계 중 데이터 전처리에 관한 부분은 다음 포스팅을 참고해주세요○ Regularization(정규화)
머신러닝 모델을 짤때, train-data set에 대해 정확도가 잘 나오는지 보고, Bias가 적절한지 판단 후에 test-data set에 general하게 적용이 되는지를 통해 variance가 적절한지 판단을 해야합니다.
만약 bias가 좋지 않다면(정확도가 높지 않다면) 네트워크를 더 깊거나 복잡하게 혹은 최적화 방법을 통해 해결하고,
Variance가 좋지 않을 때도 마찬가지로 네트워크 복잡도를 늘려서 해결할 수 있지만 가장 좋은 방법은 Data-set의 갯수를 늘리는 것이 좋다고 합니다. 일반적으로는 Regularization 방법을 많이 사용한다고 합니다.
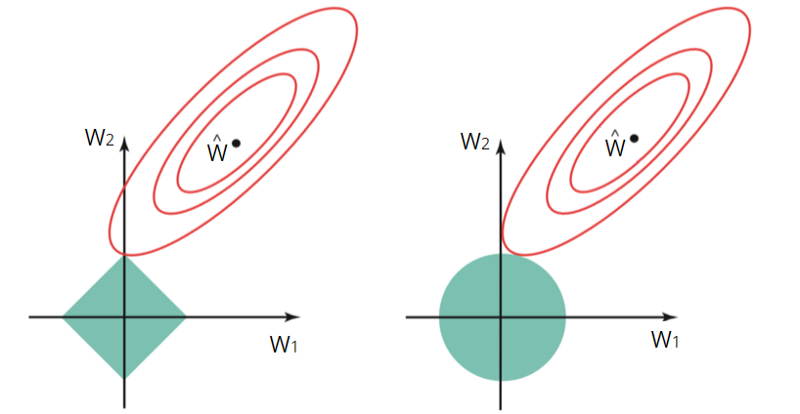
The left image shows the constraint function (green area) for the L1 and the right image shows the constraint function for the L2 -
Regularization(정규화) :
Overfitting모델의 해결 방안 중 하나로, 복잡성을 줄여(오버피팅을 줄이거나 분산을 줄여) 그 결과 train-data set에 대한 학습정도와 unseen-data에 대한 일반화 정도를 trade off하는 것. 여러 weight들 중 큰 값도 있고 작은 값도 있는데, 큰 weight를 가진 피처는 모델에 크게 반영된다. 하지만 정규화를 사용해 loss함수에 제약을 걸면 상대적으로 큰 weight라도 다른 weight와 비슷하게 weight를 업데이트 시키게 됩니다.
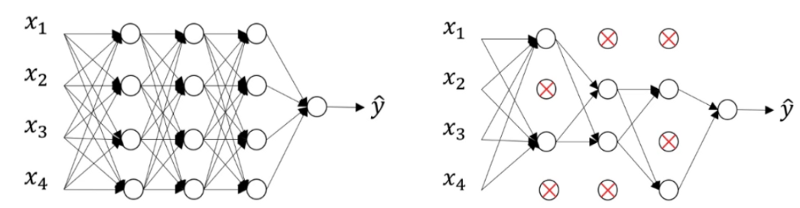
Dropout -
Regularization 방법
- loss함수에 람다*(w1+w2+..)를 붙여 상대적으로 큰 weight에 작은 상수를 곱해 weight를 줄인다.
- L2 Norm으로 정규화, 상수 람다/2m*(각 weight들의 제곱의 합)을 더하는 것. (m은 input feature수, 람다는 regularization hyperparameter로 개발자가 정하고 테스트해서 바꾸는 수이다.)
- Dropout 사용. 전체 weight을 계산에 참여시키는 것이 아니라 layer에 포함된 weight 중에서 일부만 참여시키는 것입니다.
-
케라스에서 사용
L2
model = Sequnential() model.add(Dense(16, input_shape=(1,), activation='relu') model.add(Dense(32, kernel_ragularizer=regularizers.l2(0.01)) model.add(Dense(2, activation='sigmoid')2번째 레이어에서 람다값0.01의 regularization, 결과로 loss+L2 norm의 cost function이 weight를 줄이는 방식으로 weight가 업데이트 되어 복잡도 줄어듭니다.
Dropout
# 2. 모델 구성 from keras.models import Sequential from keras.layers import Dense, Dropout model = Sequential() model.add(Dense(1000, input_shape=(1, ), activation='relu')) model.add(Dropout(0.2)) # 랜덤으로 노드 20%를 잘라준다. 0.2 - 0.3 많이 사용 model.add(Dense(1000)) model.add(Dropout(0.2)) model.add(Dense(1))'✨ AI' 카테고리의 다른 글
[AI 논문] 인공지능 최신 논문 찾아보기 / SOTA 알고리즘 찾아보기 (4) 2020.12.28 [GAN] 생성적 적대 신경망(GAN) 쉽게 알아보기 (2) 2020.04.20 [인공지능] 지도학습, 비지도학습, 강화학습 (21) 2020.04.16 [딥러닝] 선형회귀와 로지스틱회귀 (0) 2019.12.22 [인공지능] ANN, DNN, CNN, RNN 개념과 차이 (15) 2019.12.10