-
[Keras] 튜토리얼13 - CNN(Convolution Neural Network)💫 Computer Science/Python & AI Framework 2020. 1. 8. 21:47
● CNN(Convolution Neural Network)란?
합성곱 신경망(Convolutional Neural Network)은 딥러닝의 가장 대표적인 방법입니다.
주로 이미지 인식에 많이 사용된다고 합니다. 기본적인 아이디어는 이미지를 작은 특징에서 복잡한 특징으로 추상화하는 것입니다.우리가 지금까지 살펴본 일반적인 인공신경망 모델(Fully connected layer로 이루어진)은 1차원 형태의 입력형태로 한정 됩니다. 하지만 컬러 사진의 데이터는 3차원 데이터 형태로 들어오게 됩니다. 3차원으로 된 사진데이터를 FC(Fully Connected) 신경망으로 학습시키려면 2, 3차원의 데이터를 1차원으로 평면화 시켜야 합니다. 이렇게 될 경우 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 잘 추출하지 못하고 학습이 비효율적으로 이루어 질 수 있습니다.

이러한 사진 데이터가 
한줄이 되어버립니다@@ 이것을 해결하고자 이미지 공간 정보를 유지한 상태로 학습이 가능하게 만든 모델이 바로 CNN(Convolutional Neural Network)인 것입니다!

이러한 사진 데이터는 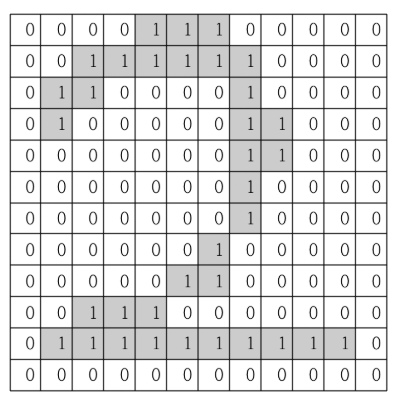
이렇게 픽셀 값을 가진 이차원 행렬로 표현됩니다. 하지만 한개의 픽셀도 RGB를 의미하는 3개의 색상값을 가지고 있으므로 1개의 픽셀은 3차원으로 구성됩니다. ○ CNN의 특징
CNN과 일반 Fully Connected Neural Network와 다른 점은,
- 각 레이어의 입출력 데이터의 형상을 유지한다.
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식한다.
- 복수의 필터로 이미지의 특징을 추출하고 학습한다.
- 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 적다.
○ CNN 모델의 구조

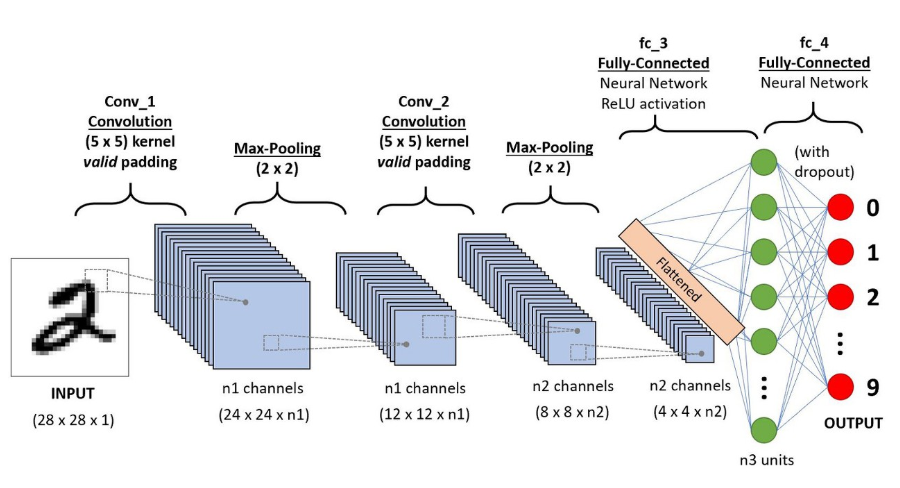
CNN의 구조는 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나누어 집니다.
- 이미지의 특징을 추출하는 부분
- Convolution Layer : 입력데이터에 필터를 적용 후 활성화 함수를 반영하는 필수 요소입니다.
- Pooling Layer : 선택적인 레이어로, Convolution 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다. Pooling 레이어에는 Max Pooling과 Average Pooning, Min Pooling이 있습니다. 정사각 행렬의 특정 영역 안에 값의 최댓값을 모으거나 특정 영역의 평균을 구하는 방식으로 동작합니다.
- 중간 부분
- Flatten Layer : 이미지 형태의 데이터를 배열 형태로 만듭니다.
- 클래스를 분류하는 부분
- Fully connected Layer
○ 레이어별 출력 데이터 산정
Convolution Layer

- 입력 데이터 높이: H
- 입력 데이터 폭: W
- 필터 높이: FH
- 필터 폭: FW
- Strid 크기: S
- 패딩 사이즈: P
Pooling Layer

○ CNN 관련 주요 용어
- 합성곱(Convolution)

: 합성곱 연산은 두 함수 f, g 가운데 하나의 함수를 반전(reverse), 전이(shift)시킨 다음, 다른 하나의 함수와 곱한 결과를 적분하는 것을 의미한다. ...? 이렇게 정의가 되어있는데 좀 난해하므로 합성곱에 관련하여 자세히 풀어쓴 포스팅을 첨부하겠습니다. 합성곱 연산 과정은 결국 Feature Map을 형성하는 것이라고 볼 수 있습니다.
- 채널(Channel)

: 컬러 이미지는 3개의 채널로 구성됩니다. 반면에 흑백 명암만을 표현하는 흑백 사진은 2차원 데이터로 1개 채널로 구성됩니다. 높이가 39 픽셀이고 폭이 31 픽셀인 컬러 사진 데이터의 shape은 (39, 31, 3)으로 표현합니다.
- 필터(Filter)


: CNN에서는 필터와 커널(Kernel)이 같은 의미입니다. 필터 파라미터는 CNN에서의 학습 대상이며 필터는 지정된 간격으로 이동하면서 전체 입력데이터와 합성곱하여 Feature Map을 만듭니다.
- 스트라이드(Strid)
: 지정된 간격으로 필터를 순회하는 간격을 의미합니다.
- 패딩(Padding)
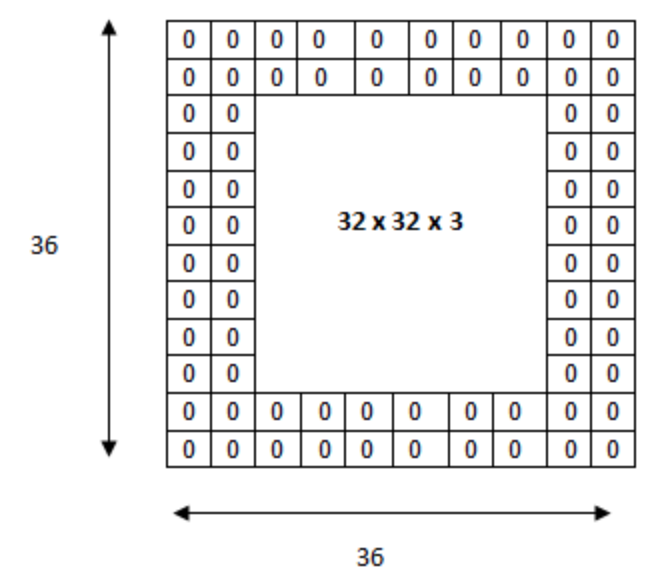
: Convolution 레이어에서 Filter와 Stride에 작용으로 Feature Map 크기는 입력데이터 보다 작습니다. Convolution 레이어의 출력 데이터가 줄어드는 것을 방지하는 방법이 패딩입니다. 패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미합니다. 보통 패딩 값으로 0으로 채워 넣습니다.
- 피처맵(Feature Map)
: Convolution Layer의 입력 데이터를 필터가 순회하며 합성곱을 통해서 만든 출력이며 액티베이션 맵(Activation Map)이라고도 합니다.
그럼 이제 케라스로 CNN을 구현해보도록 하겠습니다.
케라스 구현 코드
1234567891011121314151617# Convolution Neural Network# 가장 큰 특징은 특징을 잡는 것 lstm보다는 느리다from keras.models import Sequentialfrom keras.layers import Flatten, Densefilter_size = 32kernel_size = (3,3)from keras.layers import Conv2D, MaxPool2Dmodel = Sequential()model.add(Conv2D(7, (2,2), padding='same', input_shape=(28,28,1)))model.add(Flatten())model.add(Dense(10))model.add(Dense(10))model.summary()cs model.add(Conv2D(7, (2,2), padding='same', input_shape=(28,28,1)))
padding='same'을 적용하지 않으면 (None,27,27,7) 데이터의 갯수는 늘어나며,
픽셀을 (2,2)로 잘라서 특징 추출 피처는 중복해서 자르므로 5*5그림은 4*4개가 됩니다.
만약, padding을 적용하면 데이터의 쉐입은 (None,28,28,7)
input_shape=(None, 가로픽셀, 세로픽셀, feature) 1흑백(깊이1) 3컬러 None개 사진을 훈련
model.add(Flatten())
Flatten 2차원을 평평하게 28*28*7=5488 만들어 Dense 레이어로의 전환을 위한 레이어입니다.
model.add(MaxPool2D(3,3))
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1),
파라미터들.
# padding='valid', data_format=None, dilation_rate=(1, 1), activation=None,
# use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',
# kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
# kernel_constraint=None, bias_constraint=None)
# filters나가는 것,아웃풋/kernel_size 필터사이즈,자르는크기/strides(1,1)한칸씩 이동
# ex 6*6사이즈를 kernel_size(2,2) stride(2,2) 면 -> 2*2가 나옴
# 5*5그림에서 kernel_size(1,1) -> 5*5 // (2,2) -> 4*4
# padding의default valid// padding='same' 원래있던 이미지에 가로세로 한줄을 씌운다(0or1). 원래있던shape과 동일하게
자르는 과정 이해
model.add(Conv2D(7, (3,3), input_shape=(5,5,1)))
model.add(Flatten())
# Conv2D에서 5*5 그림을 3*3으로 자르면 다음 레이어(Flatten)으로 3*3짜리 7장이 나감 -> (3,3,7) 가로,세로,필터
# padding='same' -> 위,아래,가로,세로로 한줄씌워서 다음레이어(Flatten)으로 5*5내보냄 -> (5,5,7)
# Conv2D는 나가는 값이 같다. return_sequence필요없음 그대로 다음 레이어에 Conv2D적용 가능
model.add(Conv2D(3, (2,2), input_shape=(5,5,1))) -> (4,4,3)
model.add(Conv2D(4, (2,2))
# padding하는 이유 가장자리 픽셀데이터의 손실을 줄이기 위함
# Shape맞추기 -> Dimension맞추기
model.add(Dense(10, input_shape=(5,)))
# -> (5,10,1)로 reshape필요
model.add(LSTM(10, input_shape=(5,1)))
# -> (5,10,1,1)로 reshape필요
model.add(Conv2D(10,(2,2), input_shape=(28,28,1)))
# 레이어 모델끼리 서로 shape을 바꿔보며 상호호환해야한다.
# Conv2D -> DNN 예측값은 잘 맞을 수도 있지만 DNN -> Conv2D는 잘 안될수도
구현코드 2
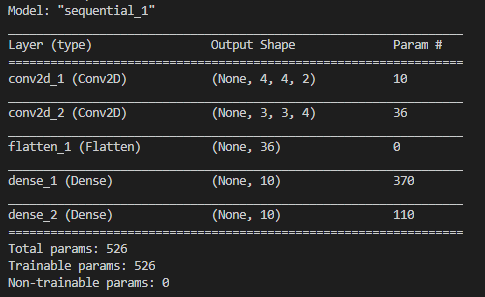
12345678910111213141516from keras.models import Sequentialfrom keras.layers import Flatten, Densefilter_size = 32kernel_size = (3,3)from keras.layers import Conv2D, MaxPool2Dmodel = Sequential()model.add(Conv2D(2, (2,2), input_shape=(5,5,1)))model.add(Conv2D(4, (2,2)))model.add(Flatten())model.add(Dense(10))model.add(Dense(10))model.summary()cs model.add(Conv2D(2, (2,2), input_shape=(5,5,1)))
model.add(Conv2D(4, (2,2)))위 두 컨볼루션 레이어를 그림으로 표현해보면 다음과 같습니다.

결과
참고한 글
'💫 Computer Science > Python & AI Framework' 카테고리의 다른 글
[캐글] 중고차 가격 예측 모델1_선형회귀 Linear Regression() (37) 2020.01.16 [Keras] 튜토리얼14(마지막) - 모델 SAVE, LOAD, Tensorboard 이용하기 (0) 2020.01.12 [Keras] 튜토리얼12 - Scikit-learn의 Scaler (0) 2020.01.05 [Keras] 튜토리얼 11 - LSTM(feat. RNN) 구현하기 (2) 2020.01.04 [Keras] 튜토리얼10 - 앙상블(ensemble) (1) 2019.12.31