-
[인공지능] 지도학습, 비지도학습, 강화학습✨ AI 2020. 4. 16. 11:42
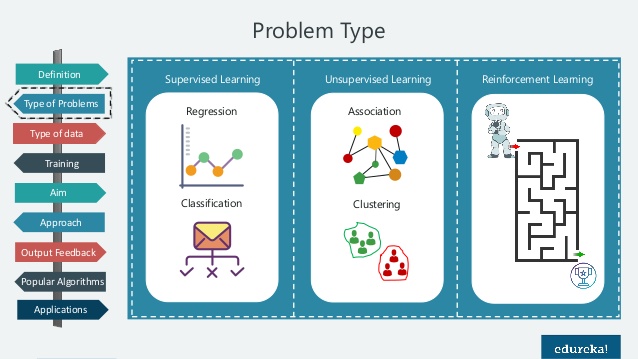
머신러닝의 학습 방법은 크게 3가지로 분류됩니다.
- 지도학습
- 비지도학습
- 강화학습
● 지도학습(Supervised Learning)
지도 학습은 말 그대로 정답이 있는 데이터를 활용해 데이터를 학습시키는 것입니다. 입력 값(X data)이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 대표적으로 분류, 회귀 문제가 있습니다.
예를 들어, 입력 데이터 셋을 3*5, 32*44 등을 주고 라벨 데이터 셋을 입력 데이터셋의 정답인 15, 1408등을 주면 해당 모델은 주어지지 않은 데이터 셋 9*3의 정답을 해결할 수 있게 됩니다.
- 지도학습 종류
1) 분류(Classification)
분류는 주어진 데이터를 정해진 카테고리(라벨)에 따라 분류하는 문제를 말합니다. darknet의 YOLO, network architecture는 GoodLeNet for image classification을 이용하여 이미지를 분류하고 있습니다. 분류는 맞다, 아니다 등의 이진 분류 문제 또는 사과다 바나나다 포도다 등의 2가지 이상으로 분류하는 다중 분류 문제가 있습니다.
예를 들어 입력 데이터로 메일을 주고 라벨을 스팸메일이다, 아니다 를 주면 모델은 새로운 메일이 들어올 때 이 메일이 스팸인지 아닌지 분류를 할 수 있게 됩니다.
2) 회귀(Regression)
회귀는 어떤 데이터들의 Feature를 기준으로, 연속된 값(그래프)을 예측하는 문제로 주로 어떤 패턴이나 트렌드, 경향을 예측할 때 사용됩니다. 즉 답이 분류 처럼 1, 0이렇게 딱 떨어지는 것이 아니고 어떤 수나 실수로 예측될 수 있습니다.
예를 들어 서울에 있는 20평대 아파트 집값 가격, 30평대 아파트 가격, 지방의 20평대 아파트 가격등을 입력데이터로 주고 결과를 주면, 어떤 지역의 30평대 아파트 가격이 어느정도 인지 예측할 수 있게 됩니다.
*Feature
머신러닝은 어떤 데이터를 분류하거나, 값을 예측(회귀)하는 것입니다. 이렇게 데이터의 값을 잘 예측하기 위한 데이터의 특징들을 머신러닝/딥러닝에서는 "Feature"라고 부르며, 지도, 비지도, 강화학습 모두 적절한 feature를 잘 정의하는 것이 핵심입니다. 엑셀에서 attribute(column)라고 불려지던 것을 머신러닝에서는 통계학의 영향으로 feature라고 부릅니다. 과거에 딥러닝 이전의 머신러닝에서는 Raw데이터를 피처 엔지니어가 직접 적절한 피처를 만들고, 머신러닝 모델의 결과로 아웃풋을 냈었는데, 딥러닝 이후로 Raw데이터를 딥러닝 모델에 넣어주면 모델이 알아서 feature를 알아내고 아웃풋을 내는 형식으로 발전하게 되었습니다. (머신러닝 모델이 피처를 알아서 찾아준다고 하여도 여전히 전처리 작업은 중요합니다.)
예를 들어 고양이, 강아지 사진은 분류한다고 하면 고양이는 귀가 뾰족하다 거나 눈코입의 위치, 무늬 등이 피처가 됩니다. 키와 성별을 주고 몸무게를 예측한다고 하면 키와 성별이 피처가 됩니다.
Feature는 Label, Class, Target, Response, Dependent variable 등으로 불려집니다.
● 비지도학습(Unsupervised Learning)
지도 학습과는 달리 정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 방법을 비지도학습 이라고 합니다. 라벨링 되어있지 않은 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 지도학습보다는 조금 더 난이도가 있다고 할 수 있습니다. 실제로 지도 학습에서 적절한 피처를 찾아내기 위한 전처리 방법으로 비지도 학습을 이용하기도 합니다.
비지도학습의 대표적인 종류는 클러스터링(Clustering)이 있습니다. 이 외에도 Dimentionality Reduction, Hidden Markov Model이 있습니다. 예를 들어 여러 과일의 사진이 있고 이 사진이 어떤 과일의 사진인지 정답이 없는 데이터에 대해 색깔이 무엇인지, 모양이 어떠한지 등에 대한 피처를 토대로 바나나다, 사과다 등으로 군집화 하는 것입니다.
지도/비지도 학습 모델(Semi-Supervised Learning)을 섞어서 사용할 수도 있습니다. 소량의 분류된 데이터를 사용해 분류되지 않은 더 큰 데이터 세트를 보강하는 방법으로 활용할 수 도 있습니다.
최근 각광받고 있는 GAN(generative Adversarial Network)모델도 비지도 학습에 해당합니다.
-
지도학습, 비지도학습의 대표적인 알고리즘
지도학습(Supervised Learning), Classification kNN Naive Bayes Support Vector Machine Decision Regression Linear Regression Locally Weighted Linear Ridge Lasso 비지도학습(Unsupervised Learning), Clustering K Means Density Estimation Exception Maximization Pazen Window DBSCAN 출처: https://wendys.tistory.com/169
● 강화학습(Reinforcement Learning)
머신러닝의 꽃이라 불리는 강화학습(RL)은 지도, 비지도 학습과는 조금 다른 개념입니다.

우리가 잘 아는 알파고는 이 '강화학습' 모델로 만들어졌습니다. 행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하는 것도 아니고 데이터가 있어도 정답이 따로 정해져 있지 않으며 자신이 한 행동에 대해 보상(reward)를 받으며 학습하는 것을 말합니다.
- 강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(environment)에서 현재 상태(state)에서 높은 점수(reward)를 얻는 방법을 찾아가며 행동(action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다.
만약 이것을 지도 학습(Supervised Learning)의 분류(Classification)를 통해 학습을 한다고 가정하면 모든 상황에 대해 어떠한 행동을 해야 하는지 모든 상황을 예측하고 답을 설정해야 하기 때문에 엄청난 예제가 필요하게 됩니다.
바둑을 학습한다고 했을 때, 지도 학습(Supervised Learning)의 분류(Classification)를 이용해 학습하는 경우 아래와 같은 개수의 예제가 필요해지게 됩니다.
강화 학습(reinforcement learning)은 이전부터 존재했던 학습법이지만 이전에 알고리즘은 실생활에 적용할 수 있을 만큼 좋은 결과를 내지 못했습니다.
하지만 딥러닝의 등장 이후 강화 학습에 신경망을 적용하면서부터 바둑이나 자율주행차와 같은 복잡한 문제에 적용할 수 있게 되었습니다. 좀 더 자세히 설명하면 고전적인 강화학습 알고리즘은 앞으로 나올 상태에 대한 보상을 모두 계산해야 하는데 실제 세상과 같이 상태 공간이 크면 현실적으로 계산을 할 수 없습니다. 최근에는 계산하는 대신 신경망을 통해 근삿값을 구함으로써 복잡한 문제를 해결할 수 있게 되었습니다.
강화학습에 딥러닝을 성공적으로 적용한 대표적 알고리즘으로는 DQN과 A3C가 있는데요. 두 알고리즘 모두 딥마인드에서 발표했으며 다른 강화학습 알고리즘의 베이스라인이 되었습니다.
[References]
https://blogs.nvidia.co.kr/2018/09/03/supervised-unsupervised-learning/
'✨ AI' 카테고리의 다른 글
[AI 논문] 인공지능 최신 논문 찾아보기 / SOTA 알고리즘 찾아보기 (4) 2020.12.28 [GAN] 생성적 적대 신경망(GAN) 쉽게 알아보기 (2) 2020.04.20 [딥러닝] Bias-Variance Tradeoff 와 앙상블 (0) 2020.01.02 [딥러닝] 선형회귀와 로지스틱회귀 (0) 2019.12.22 [인공지능] ANN, DNN, CNN, RNN 개념과 차이 (15) 2019.12.10