-
[NLP] Seq2Seq, Transformer, Bert 흐름과 정리✨ AI/NLP 2021. 9. 19. 12:23

딥러닝 기반 기계번역 발전과정
RNN → LSTM → Seq2Seq => 고정된 크기의 context vector 사용
→ Attention → Transformer → GPT, BERT => 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전
GPT : transformer 디코더 아키텍처 활용
BERT : transformer 인코더 아키텍처 활용
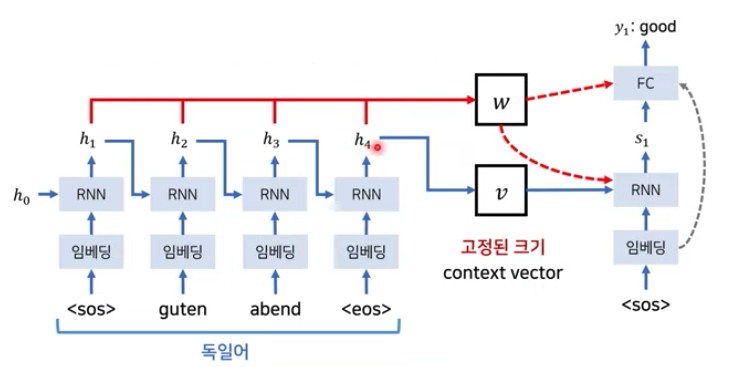
Seq2Seq Model
- encoder = <sos> quten abend <eos>
각 토큰은 임베딩 레이어를 거쳐 RNN레이어를 지나게 된다. 그러면 각 레이어의 출력값(h1, h2,.. : activation function을 지난 후의 값)이 생기게 되며 이때 각 출력값은 다음 레이어의 입력으로 들어가게 된다.(RNN이기 때문) 각 출력값(h1, h2..)는 고정된 크기의 context vector v에 모아지게 된다.
- decoder = <sos> good evening
디코더의 레이어도 마찬가지로 각 토큰이 임베딩, RNN레이어를 거쳐 출력값(s1, s2...)이 생성된다. context v 는 첫번째 레이어의 입력으로 들어가게 되고 s1으로 출력된다.
Seq2Seq Model Problem
- context vector는 가장 마지막 레이어의 출력 값이다. 인코더의 소스 문장 전체의 문맥 정보를 포함하고 있으며 병목현상이 발생하고 성능 하락의 원인이됨
- context vector를 디코더의 첫번째 레이어에만 반영하는 것이 아니라 디코더 모든 레이어에 입력으로 넣으면 성능이 조금 개선될 수 있으나, 소스 문장이 압축될때 정보가 손실되는 문제는 여전히 존재함.
SeqSeq with Attention Model
- Seq2Seq의 problem을 개선하기 위해 소스문장의 모든 레이어(각 토큰이 연결된)의 출력 전부를 입력으로 받자
- Seq2Seq 구조를 그대로 두고, h1+h2..(all hidden state values) = w(weighted sum vector)를 디코더의 RNN셀과 FC셀의 입력으로 넣는 것
디코더가 출력 단어를 만드는 과정


i : 현재의 디코더가 처리 중인 인덱스 / j : 각각의 인코더 출력 인덱스 / ci : weighted sum - 에너지 : 매번 디코더가 출력 단어를 만들 때마다 인코더의 모든 출력을 고려하는 것, s는 디코더가 인코더 출력을 고려하기 전 출력 값. eij = 어떤 h값과 가장 많은 연관성을 가지는지 수치화
- 가중치 : 어떤 단어를 가장 많이 참고하면 되는지를 적용 된 weight 예를 들어 h1는 5% h2는 15%... 총합은 1이 되는 비율 값, 상대적인 확률 값(softmax를 거친 값)
- weighted sum : 인코더의 각 출력값에 비율*가중치의 합
- weighted sum을 디코더의 입력으로 넣어줌, 즉 현재 디코더 값과 가장 연관이 있는 인코더의 출력값을 반영해 새로운 출력값을 뽑아내는 것
- attention weight(구해진 확률값)을 이용해 각 출력이 어떤 입력 정보를 많이 참고했는지 알 수 있다.
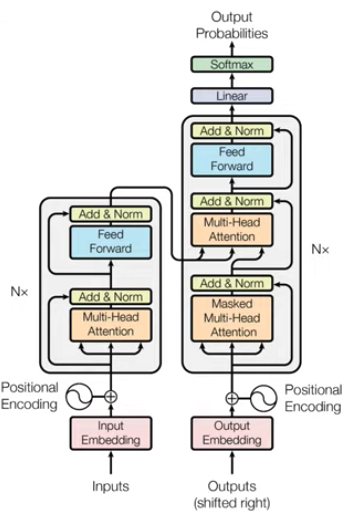
Transformer : Attention is all you need
- CNN, RNN을 전혀 필요로 하지 않고 attention만을 이용함. 그렇게 되면 RNN처럼 문장안의 각 단어 순서 정보를 주기 어려운데 이를 "Positional Encoding"을 이요해 순서 정보를 줌
- 인코더와 디코더로 구성되는 것은 동일하나 Attention 과정을 여러 레이어에서 반복. 즉, 인코더가 N개가 중첩됨
- RNN, LSTM입력단어 갯수만큼 인코더 레이어를 거쳐 hidden state를 만들지만, trans는 단어가 하나로 연결되어(중요!) 병렬적으로 한번의 인코더를 거쳐 병렬적으로 출력값 생성. 계산 복잡도 줄였다.
- RNN은 순서대로 들어가기 때문에 히든 state는 순서 정보를 가지고 있다. 이를 해결하기 위해 Positional Encoding을 Input Embedding Matrix와 element wise를 통해(더해줌) 구함 때문에 pe와 iem는 동일한 차원이여야함


- 디코더의 multi-head attention
- 2개인데 첫번째는 self-attention, 두번째는 encoder에 대한 정보를 attention 할 수 있도록 즉 각각에서 출력되고 있는 단어가 소스 문장의 어떤 문장과 관계가 많은가
동작 방식
word embedding_dim(논문에서는 512) 나는 0.12x 0.32x ............... 0.43x 오늘 ... ... ... - Input value Embedding
- Muti-head Attention
- 어텐션 실행단계. IEM+PE에서 구해진 값을 입력으로 넣음
- self attention, 입력의 각각의 단어가 서로에게 attention score를 구해, 각 단어가 어떤 단어와 높은 연관성을 가지는지에 대한 정보를 학습. 입력 문장의 문맥에 대한 정보를 잘 학습. 서로에 대한 가중치
- 잔여 학습(Residual Learning)
- 각 레이어를 거치며 단순하게 갱신하는 것이 아니라, 특정 레이어를 건너 뛰어 복사가 된 값을 그대로 넣어주는 것
- 기존 정보를 입력 받으며, 추가적으로 잔여된 부분(mutl head attention을 거친 후의 값)만 학습하도록 만들기 때문에 모델 수렴 속도가 높아지며 global optima를 찾을 확률이 높아짐
- 이전 레이어 출력 값, 건너 뛰어 복사가 된 값 ADD, 그리고 Normalization까지 수행해준 뒤 결과를 생성
- Encoder
- Attention과 Normalization 과정을 반복하며 각 레이어는 서로 다른 파라미터를 가짐
- 가장마지막 레이어 N의 출력 값을, 각 디코더 레이어의 입력으로 넣어줌
- Attention을 적용한다는 의미는 인코더의 각 입력 중 어떤 입력과 디코더의 각 뉴런에 영향을 많이 주었는지 고려하여 출력 결과를 생성하는 것
- 마지막 인코더 레이어 출력이 모든 디코더 레이어에 입력된다. E#1 → D#1 #2 #3 ...#N (디코더 파트의 2번째 multi-head attention 부분에서. 인코더의 어떤 단어와 연관이 많은지 계산하여 입력으로 넣는 부분)
Transformer의 Attention 구조(Multi-head Attention)
: 어텐션 메커니즘은 어떠한 단어가 다른 단어들과 어떠한 연관성을 가지는지 구하는 것

- Scaled Dot-Product Attention 세가지 입력 요소
- Query : 물어보는 주체
- Key : 물어보는 대상
ex. I am a teacher 각각 어떤 연관성이 있는지 구할 때, Q가 K들과 어떤 가중치 값을 가지는지 attention score들을 구함 Q: I, Key: I am a teacher / Q : am, Key : I am a teacher ... - Value : 각 attention score(value)들과 곱해 attention value를 구하는 것
- → h개의 각각의 다른 attention value를 구하는데, 서로다른 attention concept을 학습하도록 만들어 더욱더 구분된 다양한 특징들을 학습할 수 있도록 유도하기 위해(multi head)
- 인코더 디코더에서 multi-head attention 부분이 여러개가 있는데, Q, K, V를 어떻게 사용하냐만 다를 뿐 기본적인 동작 방식은 동일하다.
- 인코더-디코더 어텐션 에서는(디코더의 두번째 multi head attention 부분) 출력 단어가 Query가 되는 것이고 각 출력 단어를 만들기 위해 인코더 파트에서 어떤 단어를 참고하면 좋은지 구하기 위해 K, V를 인코더의 출력 값을 쓰는 것임.

- 루트 dk는 scale factor, key dimension으로 나눠주는 이유는 softmax함수 자체가 가지는 특성은 0근처 위치에서 gradient가 높게 형성되는 것에 반해 들쑥날쑥하여 왼쪽 오른쪽으로 이동하면서 기울기 값이 많이 줄어들기 때문에 gradient vanishing 문제를 피하기 위함임
자세한 동작 구조

위 그림에서는 임베딩 차원이 4, h가 2 Wq, Wk, Wv는 가중치 매트릭스, 4dim을 2dim으로 매핑 시키기 위해 x4*2 각 단어의 Embedding 생성 ex. love →(linear layer) Q:love, K:love, V:love 임베딩 차원이 512고 h수가 8개면 512/8 만큼의 각각의 Q, K, V가 생성됨

위 그림처럼 하나씩 연산이 아니라 행렬 곱셈 연산으로 한꺼번에 계산 그 다음, Attention value계산

그 다음 MultiHead(Q, K, V) = Concat(head1, head2, ..., headn)Wo 입력 차원과 동일한 차원 출력
Attention 종류
- transformer에는 총 3가지 Attention Layer 존재
- Encoder Self-attention
- Masked Decoder Self-attention encoder self-attention은 각 단어의 순열 전부 참고, decoder self-attention은 앞쪽 단어들만 (치팅 방지)
- Encoder-Decoder Attention Query는 디코더, Key, Value는 인코더에 있는 상황
- Positional Encoding은 주기 함수를 활용해 각 단어의 상대적인 위치 정보를 입력
BERT
- Bidirectional Encoder Reperesentation from Transformers
- transformer는 인코더는 양방향, 디코더는 왼쪽에서 오른쪽으로 처리 이름 그대로 transformer의 bidirectional한 인코드를 사용하겠단 의미
- bert있기전, GPT는 transformer에 디코더를 활용한 모델이었으며 generative training of LM. 왼쪽 단어들을 보고 다음 단어를 예측
- attention vector는 토큰의 의미를 구하기 위해 사용이 된다.
- elmo, bert의 큰 특징은 dynamic embedding이라는 점. 즉 중의성이 해소
- 학습방법
- MLM, Masked Language Model
- 문장의 랜덤한 단어 Mask 후, 예측.
- NSP, Next Sentence Prediction
- 2쌍의 문장의 순서를 학습. 순서가 맞으면 레이블 1 아니면 0
- MLM, Masked Language Model
- Bert parameters
- L : num of layers (Transformer block)
- H : hidden layer
- A : num of self attention heads

activation function으로 사용된 GeLU는 네트워크가 깊을 때 사용. - input을 single sent만 받을 수도 있고, pair of sentence를 받을 수도 있다 QA task를 전이학습하려면 pair
- bert에서 정의하는 sentence : 연속적 text 의 span이기만 하면 된다.
- bert에서 정의하는 sequence : single sent or pair of sent
→ 언어학적인 문장이 아니여도 일련의 연속한 단어들의 집합이기만 하면 된다.
BERT의 동작 과정
1. Input Representation
- 입력은 2개(or 1)의 masked sentence [CLS] 시작을 알리는 토큰, [SEP] 2개 문장일시 분리하는 부분
- input embedding은 3가지 embedding의 element wise sum으로 입력
- Token Embedding : wordpiece embedding을한 30,000 토큰
- Segment embedding : EA에 해당하는 부분인지(0) EB에 해당하는 부분인지(1)
- all embedding vector element wise sum

2. Pretraining

Task 1. MLM(Masked Language Model)
- 전체 토큰의 15% 랜덤하게 Masked
- Masked된 위치의 output이 Masked된 실제 값
- 문제, Mask는 pretrain 부분에서만 일어나고 fine-tuning(down stream)에서는 하지 않으므로 [MASK] 토큰에 대한 mismatch가 발생할 수 있다. 해결하기 위해 fine-tuning 과정에서 mask한다고 결정한 토큰들 중 80%만 실제로 mask하고, 10% 랜덤한 단어로 치환하고 10%는 mask하지 않음.
- 마스킹하고 예측하는 방식이 CBOW와 비슷하지만, CBOW는 context 토큰을 center 토큰이 되도록 학습하고 weight를 벡터로 갖고, MLM은 마스킹된 토큰을 맞추도록 학습한 결과를 직접 벡터로 갖음
- 또 w2v과의 차이점은 w2v은 softmax 연산 비용이 높아 hierachical softmax또는 negative sampling을 사용하지만 bert는 전체 vocab size softmax를 모두 계산한다.
- MASK 토큰만 학습한다면 finetuning시 이를 예측할 필요가 없다고 생각해 성능이 저하될 것이다. 때문에 MASK만 학습하는 것이 아닌 문장 모든 단어에 대한 문맥 표현을 학습한다.
Task 2. NSP(Next Sentence Prediction)
- QA나 NLI는 두개 이상 문장의 관계를 이해해야 풀어 낼 수 있기 때문에. gpt나 elmo는 두개 문장의 관계를 고려하지 않음.
- 50%는 문장 순서가 맞는 문장 pair를 사용 → Y : 1
- 50%는 문장 순서가 맞지 않는 ramdom pair 사용 → Y : 0
- 단순한 idea임에도 해당 task가 down stream의 성능을 높어 선후 관계 파악을 해야 성능이 좋은 QA, NLI task에 도움을 준다고 주장
- [CLS] 벡터의 Binary classification을 맞추도록 학습
Output Reprersentation : 출력은 final hidden state의 vector
단어의 벡터를 뱉어내는 언어모델 Bert, Elmo, GPT 차이는 무엇일까?

- emlo : 정방향 forword lstm, backward latm을 여러단계 학습후 해당 hidden state를 선형 결합
- gpt : tranformer의 디코더 블록만 사용했으므로 한쪽 방향만. masking이 뒤쪽에만.
- bert는 양쪽 방향 동시에 학습. 일정 수준의 비율로 입력 token을 masking.
'✨ AI > NLP' 카테고리의 다른 글
[CS25 1강] Transformers United: DL Models that have revolutionized NLP, CV, RL (0) 2023.03.15 [NLP] Evaluation Metric for Language Model(PPL, BLEU, ROUGE) (0) 2022.09.12 [NLP] 키워드와 핵심 문장 추출(TextRank) (3) 2021.05.10 [NLP] 자연어처리 - 한국어 임베딩 (0) 2020.10.30 [NLP] 자연어처리 - 한국어 전처리를 위한 기법들 (4) 2020.10.22