인공지능 AI
[CS25 1강] Transformers United: DL Models that have revolutionized NLP, CV, RL
Transformer: An Introduction
Attention Timeline
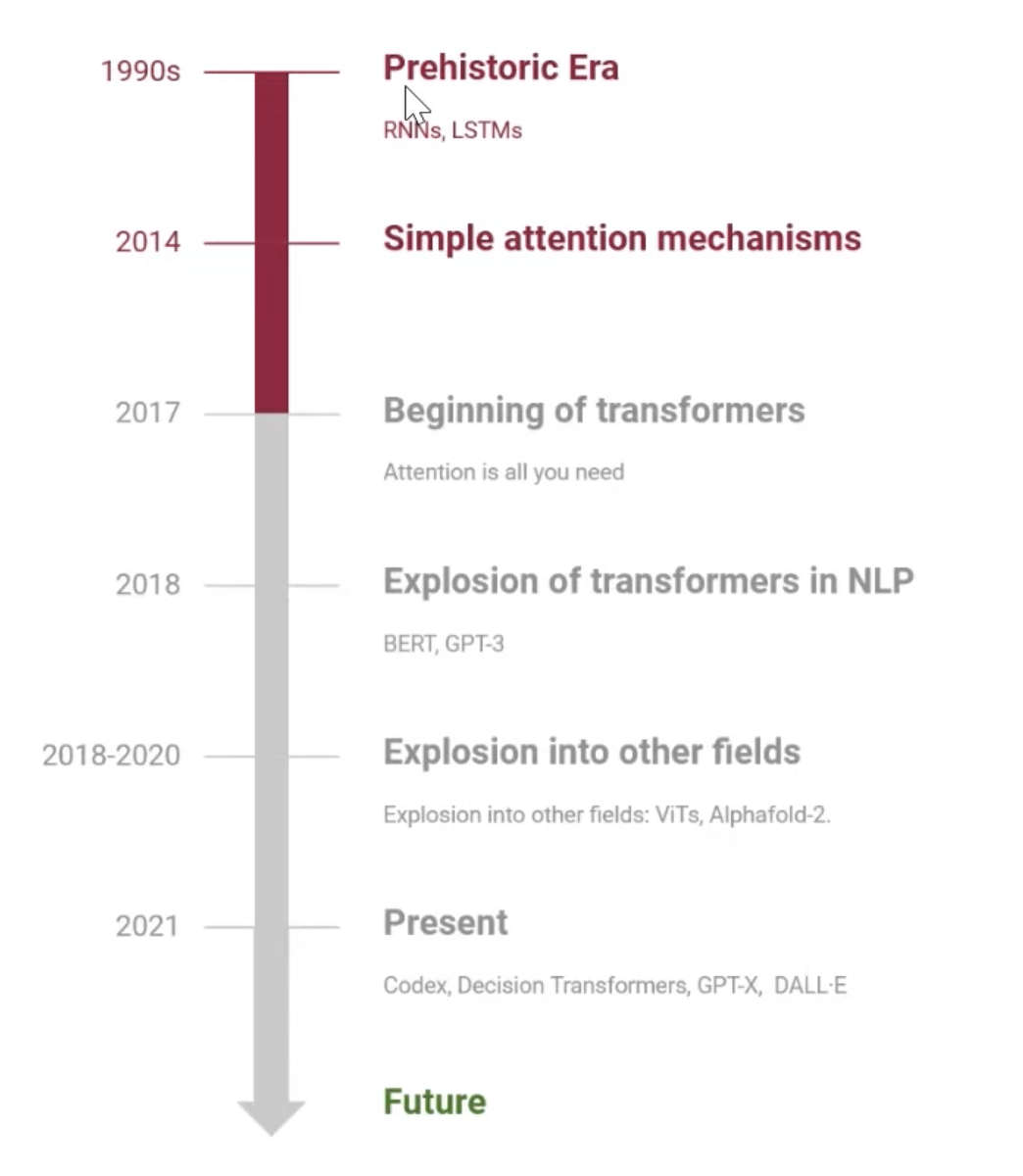
Simple attention mechanism은 딥러닝하는 사람이면 모두 아는 2017년에 나온 Vaswani의 "Attention is All you Need"라는 논문에서 시작되었다. 1강에서는 이 Attention 매커니즘의 히스토리와 어떻게 적용되었는지 살펴본다.
이전 시퀀스들의 정보를 저장하고 현재에 반영하자는 RNN 계열의 모델 LSTM, GRU.. 에서 어떻게 Attention mechanism으로까지 가게 되었는지에 대한 내용은 아래 포스팅에 작성해놓았다!
https://ebbnflow.tistory.com/316
[NLP] Seq2Seq, Transformer, Bert 흐름과 정리
딥러닝 기반 기계번역 발전과정 RNN → LSTM → Seq2Seq => 고정된 크기의 context vector 사용 → Attention → Transformer → GPT, BERT => 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전 GPT : transformer 디
ebbnflow.tistory.com
Long term sequence를 모델링이 Transformer로 인해 성능향상이 이어지자 아래와 같은 분야에도 적용이 가능해졌다.

Transformer 모델은 알파 폴드나 Offline RL과 같이 최신 트렌드의 분야에서도 널리 쓰이게 되었다. 이렇게 많은 분야에 쓰일 수 있는 이유는 RNN 계열의 모델보다 훨씬 뛰어난 성능 때문이다.
Transformer는 어떤 형태의 Sequence modeling에도 사용이 가능하다. Video understanding, finance, generative modeling 등등.. 단 모든 Sequence에 대한 Attention을 계산해야 하므로 많은 메모리와 quadratic computation complexity가 할애되어야 한다.
그리고 Challenge로는 quadratic computation cost를 줄이는 것과(e.g. Reformer..) 사람의 피드백 데이터로 언어 모델의 Alignment를 Finetuning하는 것 등이 있다. 자세한 내용은 뒷 강의에서 다루도록 한다.
Attention Mechanisms

Attention Mechanisms은 중요한 부분의 가중치를 크게 주자는 Importance Weighting으로부터 영감을 받은 것이다. 사람은 위 사진이 강아지 사진임을 구별할 때, 강아지의 얼굴 부분을 보고 강아지 사진이라고 생각하지, 잔디 부분을 보고 강아지 사진이라고 구분하지 않는 다는 것이다. 이미지에서 엣지 같이 중요한 부분의 픽셀의 가중치는 크게하고 배경 같은 부분의 픽셀의 가중치는 작게한다는 간단해보이는 원리이다. Soft attention은 가중치를 0과 1 사이가 되고 hard attention은 중요한 부분은 1 아니면 0으로 극단적으로 선택하는 것을 말한다. soft attention은 computation cost가 높지만 전체적인 데이터의 correlation을 학습할 수 있고 hard attention은 compuatation cost는 적지만, Non-differentiable하다는 단점이 있다.

그리고 Self-attention 매커니즘이 제안되기 전에 있었던 기본적인 어텐션 매커니즘은 위와 같다. Global attention은 soft attention처럼 y_t를 얻기 위해 모든 hidden layer ouput을 attention layer에 반영하는 것이고 Local attention은 모든 이전 sequence의 attention을 계산하지 않고 더 작은 window의 hidden을 attention layer에 반영하는 것이다.
Self-Attention

Query와 Key가 주어졌을 때, Query와 가장 닮은 Key를 따르는 value를 찾아야 한다. Self-attention에서는 이 key, query, value가 똑같은 문장에서부터 주어진다. self-attention을 통해서 model은 각 위치의 각 다른 token 사이에서 복잡한 interaction을 잡아낼 수 있게 된다. 어텐션 값이 계산되는 방법은 단지 weighted summation이다. 서로 연관있는 input 사이의 weight를 구하기 위해서 Transformer에서는 Scacled dot product를 similarity function으로 사용한다.
그리고 Transformer에서 중요한 방법은 Multi-head attention을 사용한다는 점이다. 이는 multiple representation을 사용할 수 있다는 의미가 된다. 예를 들어 '강아지', '사람', '동물' 이라는 단어가 있을 때 어떤 head는 강아지와 사람이 비슷한 vector를 갖도록 representation할 수 있고 어떤 head는 강아지와 동물이 비슷한 vector로 표현되게 할 수 있다.
https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a
Illustrated: Self-Attention
A step-by-step guide to self-attention with illustrations and code
towardsdatascience.com
Self-attention 동작에 관한 일러스트레이션
Ohter necessary ingredients for the recipe

그리고 Self-attention 외에도 Transformer가 강력한 이유는 Positional 인코딩과 Nonlinearities, Masking등이 있다. Transformer는 병렬적으로 이전 Sequence들의 Attention 값을 계산하기 때문에 RNN과 달리 position 정보를 줄 수 없으며 이는 문장 데이터와 같이 순서가 중요한 데이터에는 치명적이다. 이를 해결하기 위해 positional encoding을 따로 수행하며, 복잡한 Input ouput 매핑을 가능하게 하는 Nonlinearity와 미래 Token을 보지 못하게 하는 masking 트릭을 통해 다음 토큰의 예측 능력을 크게 키웠다.
Encoder-Decoder architecture

Self-attention layer에서 Linear operation을 통해 만들어진 encoding state와 ouput token이 매핑되기 위해서 위와 같이 Encoder-Decoder가 레고처럼 쌓인 것 같은 구조가 필요하다. 디코더는 인코더와 유사한 구조를 가지고 있지만 인코더의 이전 레이어를 받는다는 점이 다르다.

Transformer의 이러한 구조는 시퀀스의 모든 토큰은 모든 다른 토큰들을 볼 수 있어 각 토큰의 correlation을 잘 잡아 input과 target의 매핑이 잘 되도록 할 수 있다. 때문에 모든 Context를 동등하게 볼 수 있어 Sequence모델링에 강력하며 RNN계열에서 잘 동작하지 못했던 아주 긴 길이의 sequence모델링도 가능하다. 아주 먼 거리의 토큰도 attention weight가 크다면 크게 반영할 수 있게 된며 얼마나 멀리 떨어져 있는 것과 상관 없이 dependency를 반영할 수 있게 된다. 그리고 이전 hidden state를 계산해야만 현재 state를 구할 수 있었던 RNN 계열의 모델과 달리 Transformer는 병렬 연산이 가능하므로 gpu를 사용하면 큰 계산량에 비해 빠르게 training이 가능하다.
단점으로는 모든 token이 다른 모든 token과의 attention을 계산해야 하므로 quardratic comlexity가 필요하다. 이를 해결하기 위해 Linear complexity를 가지는 Big Bird, Linformer, Reformer 등의 모델이 제안되었다.
여기서 짧게 언급했던 내용들은 아래 블로그를 보면 자세한 설명이 되어있다.
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnames
jalammar.github.io
Applications

그리고 GPT3는 Open AI에서 나온 단방향 모델이고 이전 토큰들만 가지고 현재 State를 계산하는 language model로 이를 인코더로 사용하고 Sentiment classification, summeration, NLG 등의 downstream task를 위한 마지막 layer하나만 추가하는 식으로 사용할 수 있다. GPT3는 In-context learning을 통해서 downstream task에 대한 finetuning 없이도 여러 task를 수행 할 수 있다는 장점이 있다.
'인공지능 AI' 카테고리의 다른 글
| [CS25 2강] Transformers in Language: The development of GPT Models including GPT3 (0) | 2023.04.09 |
|---|---|
| [RL] Efficient Planning in a Compact Latent Action Space, TAP (0) | 2023.03.19 |
| [RL] Bayes-Adaptive Monte-Carlo Planning and Learning for Goal-Oriented Dialogues (0) | 2023.01.08 |
| KL-Divergence (1) | 2022.03.20 |
| Model-based Reinforcement Learning (0) | 2022.03.18 |
Contents
소중한 공감 감사합니다