AI 개발
[Keras] 튜토리얼3 - 검증손실 값(acc, loss)
● 예제 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9,10])
y = np.array([1,2,3,4,5,6,7,8,9,10])
x2 = np.array([11,12,13,14,15])
model = Sequential()
model.add(Dense(10, input_dim=1, activation='relu'))
model.add(Dense(8))
model.add(Dense(7))
model.add(Dense(6))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
model.fit(x, y, epochs=100)
loss, acc = model.evaluate(x, y)
print('acc : ', acc)
print('loss : ', loss)
y_predict = model.predict(x2)
print(y_predict)
|
cs |
Keras에서는 모델 학습을 위해 fit() 함수를 사용합니다. 이 때, 리턴값으로 학습 이력(History) 정보를 리턴합니다. 여기에는 loss, acc, val_loss, val_acc 값이 저장되어있고, 매 epoch 마다 각기 다른 값들이 저장되어 있습니다.
- loss : 훈련 손실값
- acc : 훈련 정확도
- val_loss : 검증 손실값
- val_acc : 검증 정확도
모델을 구성하여 데이터를 훈련시키고 잘 훈련된 모델인지 검증하기 위한 척도로 loss와 acc를 사용합니다.
acc는 accuracy '정확도'라는 뜻으로 값이 1에 가깝고 높을 수록 좋은 모델이라는 것을 뜻합니다.
loss는 결과 값과의 차이를 의미하므로 작을 수록 좋고 0.0000000....에 수렴할수록 좋은 모델이라는 것을 뜻합니다.
케라스에서는 matplotlib의 pyplot를 이용해서 각 결과를 그래프로 조회할 수 있습니다.
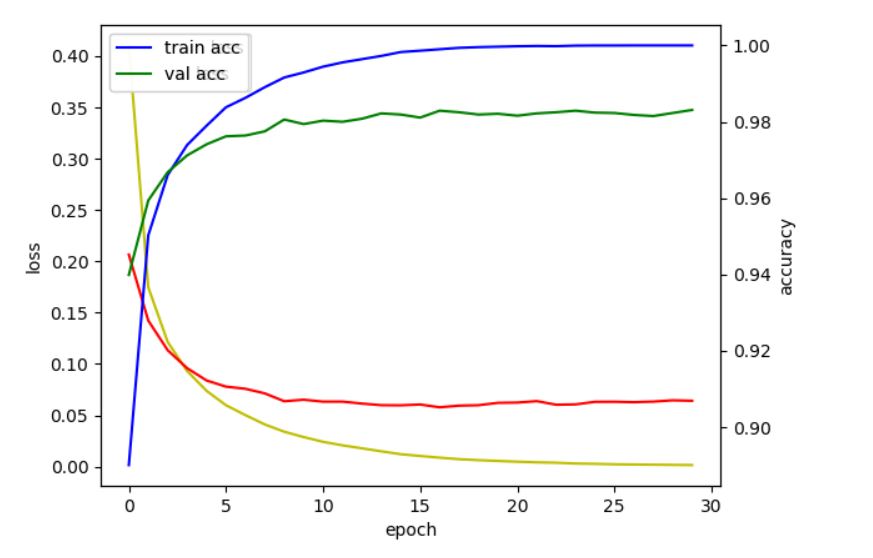
epoch의 횟수가 많아질수록(훈련횟수가 많아질수록) loss는 줄어들고 accuracy는 증가하게 되고 어느 시점이 되면 일정 값에 수렴하다가 성능이 점점 떨어지기도 합니다.(오버피팅)
● 손실 함수(loss) 종류
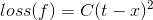
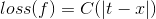
- 산술 손실 함수 : 산술값을 예측할 때 데이터에 대한 예측값과 실제 관측 값을 비교, 주로 회귀에서 사용
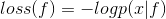
- 확률 손실 함수 : 특정 항목을 나누는 분류에서 주로 사용, 산술 손실 함수는 loss를 최소화 하는 방식으로 사용된다면 확률 손실함수는 확률을 최대화 하는 방식으로 사용된다.
- 랭킹 손실 함수 : 특정 결과값에 대한 손실을 측정하는 것이 아니라 모델이 예측해낸 결과값의 순서가 맞는지만 판별
loss='mse'
케라스에서는 주로 'mse', mean squared error값을 많이 사용합니다.
○ 평균 제곱 오차, MSE(Mean Squared Error)

평균 제곱근 편차(Root Mean Square Deviation; RMSD) 또는 평균 제곱근 오차(Root Mean Square Error; RMSE)는 추정 값 또는 모델이 예측한 값과 실제 환경에서 관찰되는 값의 차이를 다룰 때 흔히 사용하는 척도이다. 정밀도를 표현하는데 적합하다.
한마디로 오차의 제곱에 평균을 취하고 이를 제곱근 한 것이라고 생각하면 됩니다. 값이 작을수록 추측의 정확도가 높아지는 것을 뜻합니다.
metrics=['accuracy'] -> metrics=['mse']
하지만 저 예제코드에서는 아무리 연습용 코드라고 하지만 문제점이 하나 있습니다.
먼저 compile()시 파라미터로 준 metrics라는 것은 훈련할 때 보여주는 공간을 뜻합니다. 즉, 훈련을 모니터링하기 위한 지표를 선택하는 것이고 예제코드에서는 이를 'accuracy'로 지정하였습니다.
1.222 -> 1 이와 같이 1.XXX값은 1로 분류해버리는 분류모델 같은 경우에 사용하는 지표가 'accuracy'입니다.
소수점을 사용하는 회귀 모델 같은 경우는 accuracy를 사용할 수 없습니다.
그렇다면 회귀모델에서는 어떤 지표를 사용해야 할까요? 회귀모델에서 가장 많이 사용하는 지표는 RMSE와 R2입니다. 이를 구현하는 방법과 설명은 다음 포스팅에 기재하도록 하겠습니다.
'AI 개발' 카테고리의 다른 글
| [Keras] 튜토리얼5 - summery()로 모델 구조 확인 (1) | 2019.12.18 |
|---|---|
| [Keras] 튜토리얼4 - RMSE, R2 (feat.회귀모델) (1) | 2019.12.17 |
| [Keras] 튜토리얼2 - 하이퍼파라미터 튜닝이란? (0) | 2019.12.12 |
| [Keras] 튜토리얼1 - Sequential Model 구현 (2) | 2019.12.11 |
| [Keras] 케라스란? (2) | 2019.12.03 |
Contents
소중한 공감 감사합니다