AI 개발
Pandas vs PySpark
- -
Do you:
Already know Python & Pandas?
Love DataFrames?
Want to work with Big Data?
➡ Then PySpark is the answer
요즘 파이썬 & 판다스 & 넘파이 조합으로 데이터 분석을 진행 중에 있다.
아직 데이터가 많지도 않고 하나의 데이터 프레임의 크기가 크지도 않아서 저 조합으로도 충분히 커버가 가능하다.
하지만 Spark를 공부해보고자 맘 먹은 이유는
- 추후 데이터가 많아질 경우를 대비해 수평 확장성을 고려
- 추후 로그 데이터 분석이 필요할 경우 여러 시각화 플랫폼과의 연결성
- 서버가 더 생기거나 클라우드를 이용해서 클러스터를 생성할 경우 분산 처리에 대한 대비
- 빅데이터 플랫폼이 파이썬 패키지를 이용한 분석보다 쾌적한지에 대한 의문과 호기심
등이 있다.
PySpark로 잃는 것과 얻는 것
Gain
- Work with big data
- Native SQL
- Decent Documentation
Lose
- Amazing Documentation
- Easy plotting
- Indices
Apache Spark의 핵심 Concepts
Distributed Compute
- YARN, Mesos, Standalone cluster, kubernetes
Abstractions
- RDD - Distributed Collection of objects
- Dataframe - Distributed Dataset of tabular data(Integrated SQL, MLlib)
Immutable
- Change create new object references
- Old version are unchanged
Lazy Evaluation
- Compute does not happen until output is requests
Spark 데이터 구조와 동작 원리의 자세한 설명은 2편에서 하고 오늘은 Pandas와 Pyspark만 비교해보자
Pandas vs PySpark : Syntax 차이점
# Pandas
df = pd.read_csv('sample.csv') # load csv
df # show df
df.columns # show columns
df.rename(columns = {'old': 'new}) # column name 변겅
df.drop('mpg', axis=1) # drop column
df[df.mpg > 20] # filtering
df[(df.mpg > 20) & (df.cyl == 6)] # operation
import numpy as np
df['logdisp'] = np.log(df.disp) # trasformation
df.hist() # histogram
# PySpark
df = spark.read.options(header=True, inferSchema=True).csv('sample.csv') # load csv
df.show() # show df
df.show(10)
df.columns # show columns
df.dtypes
df.toDF('a', 'b', 'c') # column name 변경
df.withColumnRenamed('old', 'new')
df.drop('mpg')
df[df.mpg > 20] # filtering
df[(df.mpg > 20) & (df.cyl == 6)] # operation
import pyspark.sql.functions as F
df.withColumn('logdisp', F.log(df.log(df.disp)) # transformation
# numpy 쓸 수 있지만 되도록 built-in function 사용할 것
df.sample(False, 0.1).toPandas().hist() # histogram두 가지 문법이 완전히 똑같은 것도 있고 약간 다른 것도 있으나,
pandas에 익숙한 파이썬 유저라면 쉽게 사용이 가능할 것 같다.
PySpark는 히스토그램 기능을 제공하지 않지만, 판다스로 변환 후 사용이 가능하다.
그말인 즉슨 pandas에서 할 수 있는 것을 모두 PySpark로 변환해서 사용이 가능하다는 뜻.
하지만 데이터의 크기가 클 경우 메모리가 run out 될 가능성이 있다.
PySpark 사용시 주의할 점
- 반드시 built-in function을 이용할 것
- 파이썬과 드라이버 클러스터에 있는 패키지를 같은 버전으로 사용할 것
- built-in UI 확인할 것 http://localhost:4040
- SSH port forwarding
- Spark MLlib를 적극 활용할 것 (사이킷런과 거의 비슷)
- 모든 로우에 대해 반복문을 실행하지 마라(pandas는 할 수는 있음)
- 하드코딩 하지 말고 spark-submit을 이용해라
- 필터링하고 판다스로 변환할 경우 필터링 후 변환해야함(df.limit(5).toPandas())
data in JVM
PySpark를 사용할 때 스파크의 executors는 파이썬을 전혀 사용하지 않는다.
데이터는 JVM안에 있기 때문에 그런데, 일단 스파크는 단일 스레드에서 실행되는 것이 아니다.
따라서 스파크가 단일 스레드에서 실행될 경우 Pandas가 훨씬 더 좋은 성능을 내는 상황이 있다.
그러므로 스파크는 여러 컴퓨터 및 여러 작업을 실행하는 각 컴퓨터에서 사용할 때 빛이난다 ✨
SQL
Pandas는 native SQL syntax을 지원하지 않지만 PySpark는 지원한다.
때문에 SQL 데이터를 데이터 프레임으로 바꿀 때는 PySpark 가 더 좋다
df.createOrReplaceTempView('foo')
df2 = spark.sql('select * from foo')
일단 Spark는 'Lazy' 하다는 것을 기억해야 한다.
Lazy Evaluation은 output을 내야할 때 모든 operation 이 일어나고 그 전에는 아무일도 하지 않는 다는 것을 의미한다.
위 코드의 1번째 줄인 상태는 아직 Reference만 만든 것 뿐 아무 연산이 일어나지 않은 것이다.
Pands PySpark Koalas

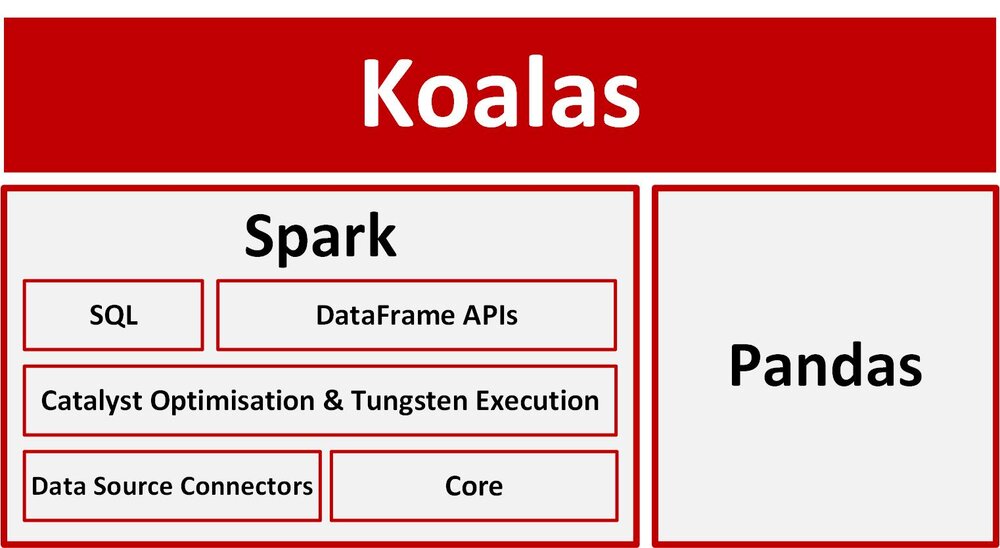
그리고 판다스랑 스파크를 선택해야 하는게 아니라 이 둘을 조화롭게 사용하는 것이 좋다고 한다.
거기다 databricks의 Koalas 프레임워크까지 곁들이면 더 좋다고 한다.
참고링크
많은 양의 데이터일 경우 pandas는 비효율적일 수 있는데 이를 위해 Koalas라는 라이브러리가 나왔다고 한다.
영화 평점 데이터를 로드하는 데서 이들의 차이를 살펴보자
# PySpark
from pyspark.sql.functions import col
movies_with_ratings = movies_df.join(ratings_df, movies_df.movieId == ratings_df.movieId)
(movies_with_ratings
.groupBy("title")
.count()
.orderBy(col("count").desc())
.show(10, False))
# Koalas/Pandas
koalas_movies_with_ratings = ks.merge(koalas_movies_df, koalas_ratings_df)
koalas_movies_with_ratings
.groupby('title')
.size()
.sort_values(ascending=False)[:10])
# Spark SQL
spark.sql("""
SELECT title, COUNT(*) as CNT
FROM movies
LEFT JOIN ratings ON movies.movieId = ratings.movieID
GROUP BY title
ORDER BY CNT DESC
LIMIT 10
""").show(10,False)
References
https://www.youtube.com/watch?v=XrpSRCwISdk
https://python.plainenglish.io/koalas-or-pyspark-disguised-as-pandas-24ab394a1b88
https://www.advancinganalytics.co.uk/blog/will-koalas-replace-pyspark
'AI 개발' 카테고리의 다른 글
| [Python] collections & itertools 의 유용한 함수들 (0) | 2021.09.02 |
|---|---|
| [Pandas] 메모리 줄이기 read_csv, chunk, multiprocessing (0) | 2021.07.01 |
| 같은 글자의 유니코드가 다를때, 정규식이 먹지 않을때 (0) | 2021.05.17 |
| [Pandas] pandas 꿀팁(?) (0) | 2021.05.17 |
| [Docker] ML + NLP Dockerfile 만들기 (0) | 2021.05.11 |
Contents
소중한 공감 감사합니다