자연어 NLP
[NLP, RL] Offline RL for Natural Language Generation with Implicit Q Learning, ILQL
Offline RL for Natural Language Generation with Implicit Q Learning(ILQL)
Link : https://arxiv.org/pdf/2206.11871.pdf
LLM(Large Language Model)은 User specified task를 완성시키는데는 일관성이 없을 수 있다. 이를 해결하기 위해 정확한 데이터로 Supervised finetuning하거나 RL로 finetuning하는 방법이 사용되었다. 이 논문에서 제안하는 ILQL은 novel offline RL 알고리즘을 활용해 전통적인 RL의 flexible utility optimization과 Simplicity, Stablility가 강점인 SL을 동시에 이용하여 Language model을 Finietuning하는 알고리즘을 제안한다.
ILQL은 Dynamic programming방법을 기반으로 하며 Implicit dataset support 제약 조건과 함께 Value conservatism을 혼합한 방법이다. 이를 통해 Value function을 학습하고 LM generation을 utility가 maximizing되는 쪽으로 가이드하는데 사용된다.
그리고 특히 언어 생성에 있어서 유해한 발언, 욕설 등을 분류하기 위한 주관적인 판단 기준은 높은 분산을 가지는 보상 함수로 볼 수 있고 ILQL에서는 이 높은 분산을 가지는 보상 함수를 어떻게 최적화 할 수 있는지 보여준다. 또 Offline RL이 Language Generation 환경에서 유용할 수 있는 경우에 대한 분석도 제시하고 있다.
Introduction
LM은 많은 양의 corpora를 학습함으로써 Text를 표현하며 이는 아주 다양한 Language-based task에 적용될 수 있다. 그리고 최근에는 파인튜닝 없이 다운 스트림 태스크를 학습할 수 있는 prompt based method에 대한 연구도 많이 이루어 졌다. 이처럼 일부 문제만 가지고 학습된 Standard unsupervisded LM은 큰 corpora의 Down knowledge를 Distilling할 때는 꽤나 효과적이다. 하지만 이는 User-specified task를 풀기는 서투른 문제점이 있다.
RL은 Utility function을 사용해서 어떤 문제를 표현할 수 있다면 LM을 User specified task에 적용할 수 있는 효과적인 프레임워크가 될 수 있다. 또, Offline RL은 존재하고 있는 데이터를 활용해서 Supervised learning의 ability와 Online RL의 Optimization power를 합친 Learning 패러다임을 제공할 수 있다. 하지만 현대의 방법들은 높은 시스템 complexity와 expensive human interaction이 많이 필요하다는 단점이 있다. 따라서 현실적인 RL을 위해서는 다음과 같은 몇가지 컨디션이 필요하다고 저자들은 주장한다.

- Easy to use
- 근본적인 알고리즘과 workflow는 simple, stable, scalable 해야한다.
- Able to optimzer user specified reward
- 알고리즘은 LM을 high-level task goal(e.g. book a flight)부터 low-level 언어적인 미묘함(e.g. avoiding rude or toxic speech)까지 아우르는 user defined reward function을 maximizing하는 쪽으로 활용 할 수 있어야 한다.
- Practical in interactive settings
- system은 desired 속성으로 text generation하는 것 부터 dialogue task와 같이 turn-taking하는 다양한 task를 handle할 수 있어야 한다.
- Able to leverage existing data
- expensive and time-consuming online human interaction 대신 인터넷에 이미 존재하는 아주 많은 데이터를 활용하는 것은 필수적이다.
- Temporally compositional
- 데이터의 평균 행동에 비해 상당한 개선을 달성할 수 있어야 한다. best behavior만 copying하는 것이 아닌 리워드, task 다이나믹스, near optimal generation이 가능한 언어 사이의 근본적인 패턴을 distilling out해야 한다. 데이터셋이 오직 task에서 평범한 성능만 보여주는 경우에서도.
이전 offline RL을 language task에 활용한 연구들은 dynamic programming에 근거하고 있어 temporal compositionality condition은 만족하지만 system complexity, hyper parameter instability, slow training time이라는 단점이 존재한다.(condition 5는 만족하지만 1을 만족하지못함)
또는 conditional imitation 이나 dataset value learning에 근거한 방법들은 simple, stable하지만 stiching benefit of RL은 가지고 있지 않다.(condition 1은 만족하지만 5를 만족하지 못함)
그래서 condition 5개를 모두 만족하는 method를 이 논문에서는 제안하고 있는데, dynamic programming에 근간하지만 implicit data support constraint를 활용한다. 이는 안정적이면서도 적은 training time 이 필요하고 이전 연구들에 비해 flexible decoding process을 제공한다. 특히 transformer 기반 language model을 finetuning 했는데 finetuned model은 각 토큰마다의 Q function과 Value function을 predict 하게 된다. 그리고 training time 동안 value function을 Q function의 upper-expectile 에 fitting 함으로써 iterative policy improvement를 수행하게 된다. 그리고 inference때는 trained value function을 LM의 log prob에 perturb를 주기 위해 사용되며 이는 LM이 specific utility를 maximize하는 ouput을 내도록 움직이게 한다.
이논문의 contribution은 크게 2가지가 있다.
- LM을 위한 novel offlie RL 알고리즘인 ILQL은 stable optimization process를 사용해서 flexible하게 높은 성능을 가지는 policy를 sub-optimal data와 임의의 sequential decision making setting에서 learning할 수 있다.
- ILQL의 많은 다양한 utility function에 일관적으로 좋은 성능을 보여주고, 이전 연구들보다 stable할 뿐 아니라 stochastic 하거나 subjective한 reward function을 optimize하는 독특한 능력을 보인다. 또한 ILQL의 sub-optimal하거나 일반적이지 않은 data distribution에 대해서도 optimal behavior을 발견하는 능력도 보인다.
Related Work
기존에 online RL이 nlp에 적용된 경우는 번역이나 요약같은 task들이었으며 이마저도 dialogue task와 같이 multiple step의 human interaction이 필요한 task 같은 경우 RL을 사용하기 어렵다. 그리고 offline RL이 nlp에 사용된 경우도 많은 연구가 있었지만, 대부분 condition 1에서 얘기한 SL정도의 레벨로 simplicity, stability, ease-of-use를 만족한 방법은 없었다.
그리고 이전 연구("GPT-critic: Offline reinforcement learning for end-to-end task-oriented dialogue systems")에서는 action space를 utterence level로 정의하고 결과는 training 동안 expensive decoding process를 낳게 한다. action space를 token 레벨로 정의한 다른 논문("Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control. International Conference on Machine Learning")도 있지만, training time에 LM으로부터 likelihood를 querying하는 것이 요구되며, 이는 complexity와 잠재적인 소스 에러를 합치고 computational cost를 증가시킨다.
e.g. I have a dog / I have a cute dog 가 있으면 utterence는 2개 action, 이지만 token-level은 5개 토큰으로 아주 많은 액션을 만들 수 있음
그래서 이 논문에서 제안하는 방법은 aciton space를 per-token으로 계산하되, training time에 generation을 simulate하지 않고 fully self-constrianed way를 통해 모델을 학습한다. 이는 implicit dataset support constraint와 discrete per-token aciton space의 이점을 취하는 novel policy extraction 방법을 함께 사용함으로써 달성될 수 있다.
비슷한 이전 연구들은 Monte carlo value estimates를 사용한 policy extraction이라고 볼 수 있고, 이는 fully dynamic programming 방법들(e.g. full q learning or actor-critic)과 비교해서는 suboptimal하지만 효율적이라는 장점을 가지고 있다. 이 논문에서 제안하는 방법은 desired task를 위한 데이터셋들이 매우 suboptimal할 때 single step 접근법들에 비해 최종 성능에서 상당한 성능 향상을 이끌 수 있다는 것을 보여준다.
Preliminaries: Language Generation as a RL task
Token-level POMDP
이 논문에서는 Language generation task를 partially observable Markov decision process(POMDP)로 정의하였다. POMDP set은 S, A, O, T, Z, \mu_0, R, \gamma로 정의되어 있고, 각 time step의 history token들을 에이전트의 observation O로 정의하였다. 그리고 action A는 모든 가능한 next 토큰이다. (h_t={t_0, t_1, .. t_{t-1}, a_t=t_t}
Value-based offline RL
Offline RL에서의 목적은 suboptimal behavior policy pi_beta로 생성된 static dataset D로부터, hightest discounted culmulative reward를 얻을 수 있는 optimal policy pi를 learning하는 것이다.
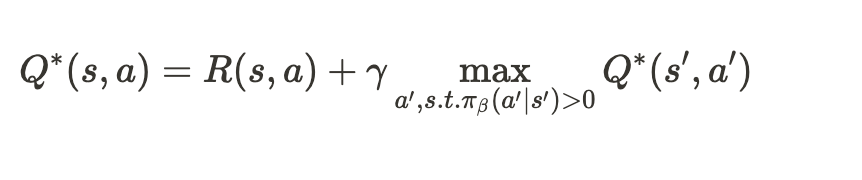
IQL(Implicit Q learning)
여기서는 pi learning을 위해 IQL 알고리즘을 사용하였다. IQL은 데이터셋에 있는 action에 constrained된(in-dataset action) Bellman optimality equation을 approximate한다. IQL은 직접적으로 support constraint를 주는 것이 아니라, expectile regression을 이용해서 constraint를 준다. 그리고 upper exectile value function을 fitting하는 것과 Q function을 backup하는 것을 explicit policy 없이 반복한다. "IQL의 key idea는 각 state마다 Dataset의 분포를 따르는 upper expectile of the value distribution를 approximation하는 것이다" 이렇게 되면 OOD action에 대해 explicit하게 constraint를 주거나 regularzation을 주지 않아도 된다.
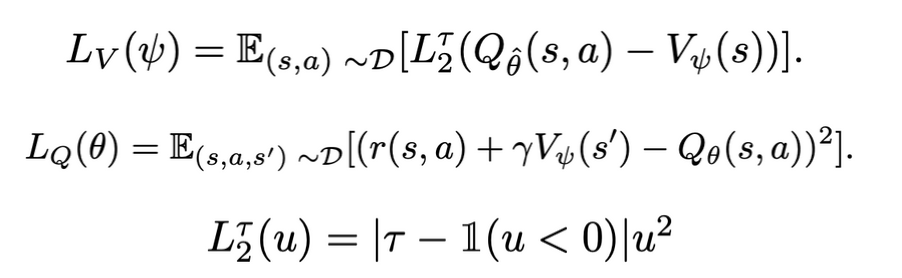
tau > 0.5라면 맞추고 싶은 expectile V, 즉 estimator가 target보다 크면 weight를 적게 준다. 이렇게 되면 Q를 데이터셋안에 있는 action 중 좋은 Q를 학습할 수 있게 된다. tau 0.5면 MSE이고(mean regression) tau=1이면 데이터셋에 있는 것 중 가장 좋은 Q를 학습할 수 있다. mean을 맞추는 것이 아니라 90% expectile을 맞출 수 있게 된다.
Large target value는 large value를 반영하는 단일 action만 반영하는 것이 아니라 stochasity에 의해 우연히 발생한 action의 value도 반영할 수 있다(lucky sample). 그래서 action distribution에 대해서만 기댓값을 근사하는 별도의 Q function model
Implicit Language Q Learning(ILQL)
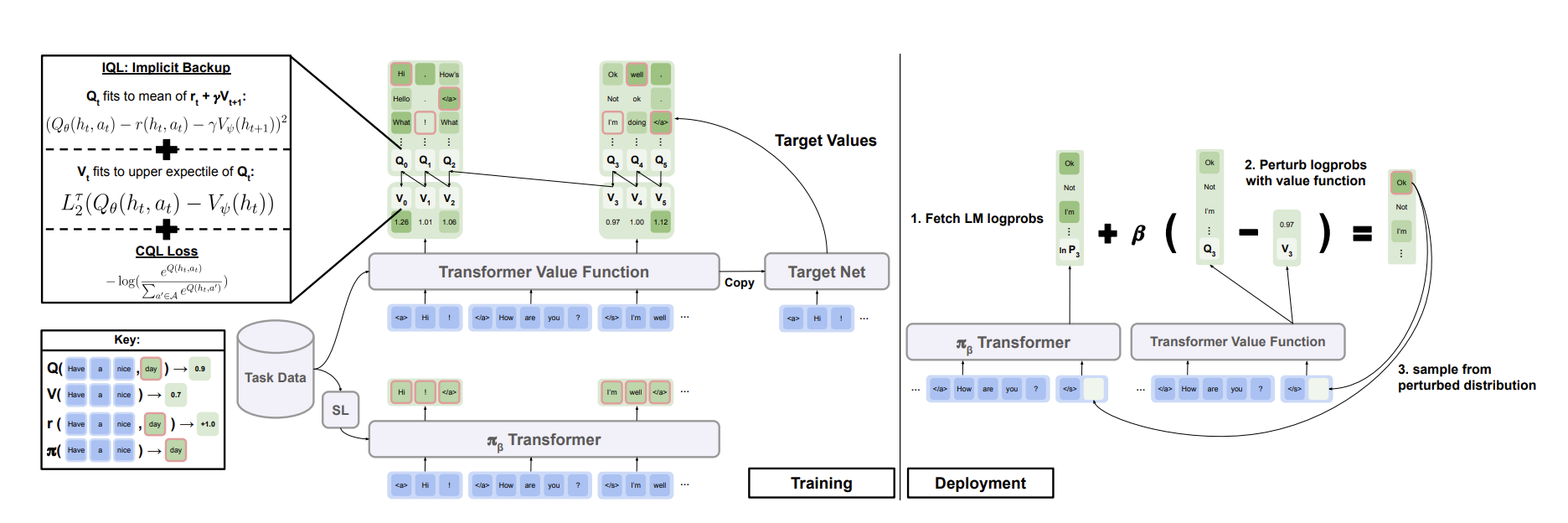
이 논문의 main contribution은 NLP task를 위한 offline RL 알고리즘이다. ILQL은 특히 user-specified reward function으로 LM을 튜닝할 때, 간단하면서도 효과적인 training을 위해 디자인 되었으며 standard supervised learning의 workflow와 매우 유사하다.
IQL -> ILQL
ILQL은 NLP task를 정의하기 위한 token-level POMDP를 풀기 위해 IQL이 확장된 알고리즘이며 아래와 같은 수정 사항이 있다.
- Partially observable language generation task를 sequence model로 통합
- 직접적으로 behavior policy에 learned value를 purturb하는 policy extraction method 를 사용함. 이는 actor pi를 직접적으로 학습한 것보다 nlp task에서 성능이 더 좋고 안정적이다
- cql regularizer를 Q function에 더해서 policy extraction step에서 발생하는 calibration issue(자주 발생하지 않는 token임에도 Value가 높으면 zero에 가깝지 않는 prob를 낳는 over smooth현상 in pi_\beta)를 해결
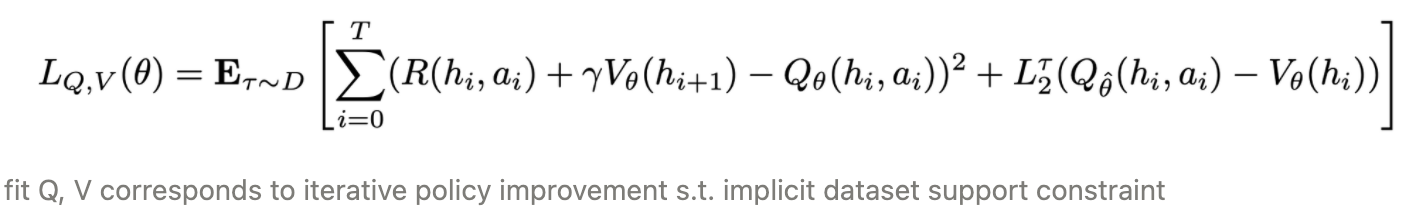
POMDP setting에 맞게 IQL loss를 위처럼 변경하였다. 매 time step에서 각 transition을 샘플하는 IQL과 다르게 partial observability를 다루기 위해 token의 sequece를 샘플하고 V는 full history에 근거해 predict된다.
Policy extraction
IQL은 AWR policy extraction을 사용한다. AWR은 log-likelihood loss로 만들어진 weight(e^{\beta(\hat{Q}-V)})로 weight된 Q를 이용해 policy를 추출하는 것을 말한다. Q-V인 advantage weight는 high-variance gradient를 초래해서 LM의 training을 unstable하게 만든다. 그러나 policy extraction과 value learning process는 독립적이므로 optimal policy model을 learning하는 것 대신 learned Q, V로 직접적으로 purturb된 behavior policy를 사용해서 inference때 action을 sampling한다.
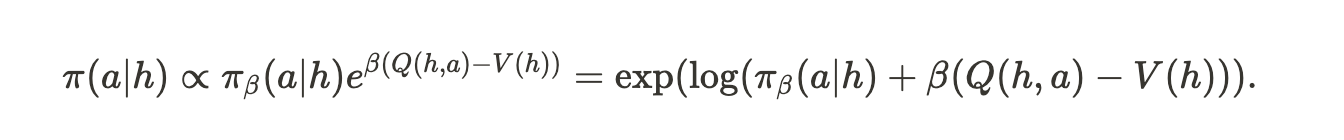
이렇게 되면 actor pi를 training하지 않고 behavioral model pi_beta만 이용해서 policy extraction을 할 수 있다. 이러면 training이 안정적인 supervised finetuning objective가 된다.
그런데 이렇게 policy extraction을 하면 offline RL에서 큰 문제로 다루어지는 over estimate문제가 있다. pi_beta에서 자주 등장하지 않는 토큰이 높은 value를 얻게되는 sample 즉 안좋은 value를 learning하게 되는 sample 이 inference에 자주 sample 된다. 이를 해결하기 위해서 top p filtering, tuning temperature paramter, explicitly push down ood q-value를 사용할 수 있고 이 논문에서는 후자를 사용했으며 CQL논문에 등장하는 CQL with a uniform KL regularizer를 loss term에 더했다.
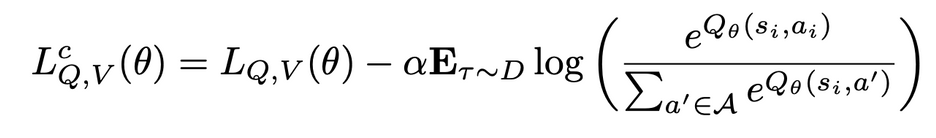
CQL에서는 continous q distribution이고 여기서는 discrete기 때문에 위처럼 식이 바뀌고 이는 standard cross entropy term과 동일하다. 이 텀 없이 AWR만 사용하거나 AWR없이 이 term이 없는 것 둘다 안좋았고 둘이 함께 사용하면 cql weight alpha에 robust했다.
Architectures for ILQL
small GPT-2를 base model로 사용했고 사용된 모델은 모두 transformer이다. value function transformer는 3개의 MLP head를 가지고 있으며 두개의 각각 독립적으로 초기화된 trained Q head와 1개의 V head가 있다. 각 헤더는 두개의 레이어로 이루어져 있고 hidden dimension은 transformer embedding dimension의 2배이다. target Q value는 Polyak averaged target Q head의 minumum predcition이며(\hat{Q} = min(Q_1, Q_2), standard LM처럼 auto-regressive causal masking을 사용하면 전체 시퀀스에 대해 Bellman update를 병렬로 수행할 수 있다.
Experiment
실험은 Multi-step Offline RL Wordle task와 NLP Generation task(Dialogue), Ablations 들로 꽉 채워져 있고 자세한 내용은 생략함.
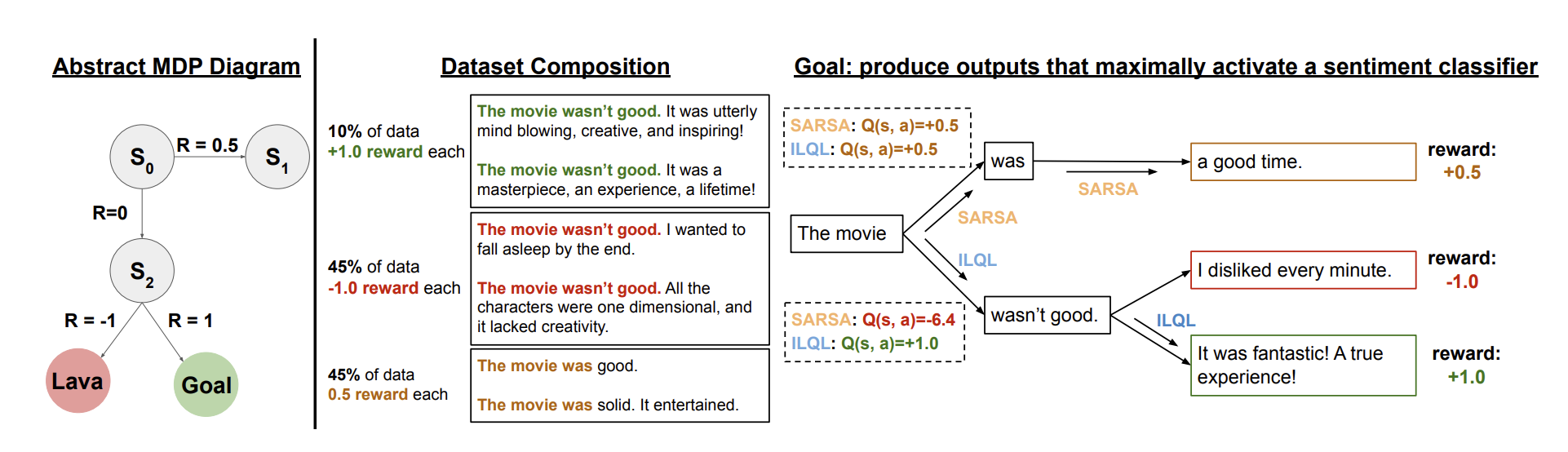



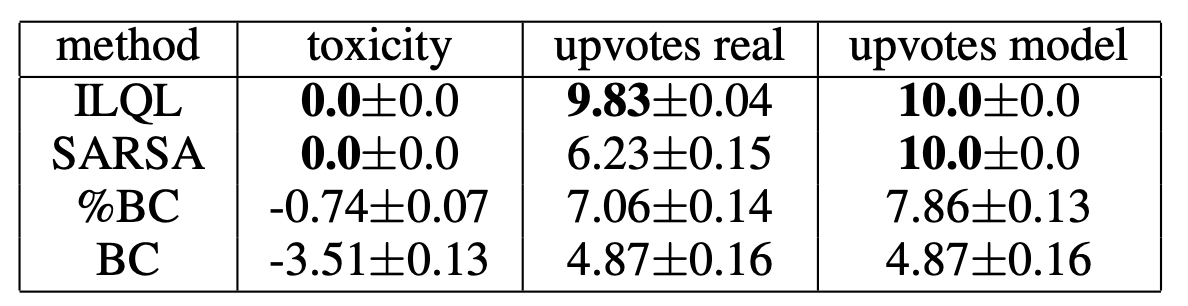



Contents
소중한 공감 감사합니다