AI 개발
[Keras] 튜토리얼 11 - LSTM(feat. RNN) 구현하기
● RNN(Recurrent Neural Network)란?

RNN(Recurrent Neural Network)은 일반적인 인공 신경망인 FFNets(Feed-Forward Neural Networks)와 이름에서 부터 어떤 점이 다른지 드러납니다. FFNets는 데이터를 입력하면 연산이 입력층에서 은닉층을 거쳐 출력층까지 차근차근 진행되고 이 과정에서 입력 데이터는 모든 노드를 딱 한번씩 지나가게 됩니다. 그러나 RNN은 은닉층의 결과가 다시 같은 은닉층의 입력으로 들어가도록 연결되어 있습니다.
즉, FFNets는 시간 순서를 무시하고 현재 주어진 데이터만 가지고 판단합니다. 하지만 RNN은 지금 들어온 입력데이터와 과거에 입력 받았던 데이터를 동시에 고려합니다.
○ RNN의 사용
RNN은 위에서 설명한 특성 때문에, Sequence Data를 다루는데 크게 도움이 됩니다. 예를 들어, RNNs은 글의 문장, 유전자, 손글씨, 음성 신호, 센서가 감지한 데이타, 주가 등 배열(sequence, 또는 시계열 데이터)의 형태를 갖는 데이터에서 패턴을 인식하는 인공 신경망 입니다.
시계열 데이터
: 데이터 관측치가 시간적 순서를 가진 데이터이다. 변수간 상관성이 존재이 존재하는 데이터를 다루며 연속하거나 불규칙적인 데이터를 다루지는 않는다. 주로 과거의 데이터를 통해 현재의 움직임과 미래를 예윽하는데 사용된다.
RNNs은 궁극의 인공 신경망 구조라고 주장하는 사람들이 있을 정도로 강력합니다. RNNs은 배열 형태가 아닌 데이터에도 적용할 수 있습니다. 예를 들어 이미지에 작은 이미지 패치(필터)를 순차적으로 적용하면 배열 데이터를 다루듯 RNNs을 적용할 수 있습니다.
○ RNN의 수식
Xt : 시간에 따른 입력값
St : state로 이전 시간의 hidden state값과 현재 시간의 input값에 의해서 계산되는 값(메모리 부분)
Ot : 시간에 따른 출력값
U,V,W : 가중치(맨 처음의 S는 0으로 초기화)
함수f : 비선형 함수로 보통 ReLU나 tanh를 사용
이 함수들을 사용하여 출력값의 범위를 제한해주고, 전 구간에서 미분이 가능하게 하여 역전파(backpropagation)가 잘 적용되도록 합니다.
○ RNN의 동작과정
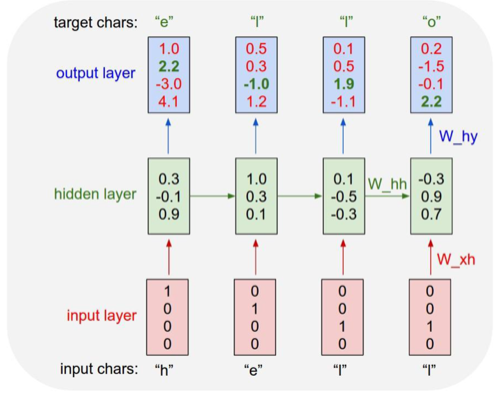
위의 그림은 문자가 주어졌을때 다음 문자를 예측하는 RNN모델입니다. 예를들어서 'helo'를 입력하면 'hello'를 출력하게 만드는 모델입니다. 여기서는 [h,e,l,o] 4가지 알파벳만 사용하기 때문에 각각을 one-hot vector로 바꾼다면 h는 [1,0,0,0], e는 [0,1,0,0], l는 [0,0,1,0], o는 [0,0,0,1]로 나타낼 수 있습니다. 그리고 이 값을 입력해 주고, [0.3,-0.1,0.9]라는 h1상태를 만들었습니다. 이것을 바탕으로 y1인 [1.0,2.2,-3.0,4.1]를 만들었습니다. 이것과 마찬가지로 다음 상태들을 생성할 수 있습니다.(모두 갱신할 수 있습니다.) 이렇게 순차적인 방향으로 나아가는 것을 순전파라고합니다. RNN도 다른 신경망들처럼 정답이 필요합니다. 모델에 정답을 알려주어 보다 더 정확한 parameter값을 갱신할 수 있습니다. 위의 예에서는 h-e-l-l-o순서로 정답입니다. output layer에서 초록색 글자 부분은 정답을 의미하는데, one-hot vector로 변환된 정답의 인덱스 부분을 뜻합니다.이 정보로 역전파(backpropagation)을 수행하여 parameter값을 갱신해 나갑니다. 여기서 말하는 parameter란 W_xh, W_hy를 뜻합니다. 즉, input layer의 결과값, hidden layer의 결과값을 의미합니다. (출처)
※one-hot vector?
one-hot 벡터는 하나의 차원만 1이고 나머지 모든 차원들은 0으로 채워진 벡터입니다. 만약 위의 예처럼 h,e,l,o 4가지 문자가 있다면 이것을 표현하기 위해서 4개짜리 벡터를 하나 만들고, 그 문자가 해당되는 자리에 1을 넣고 나머지 자리들에는 0을 넣는것입니다.([h자리,e자리,l자리,o자리]이렇게 표시를 합니다. 따라서 h는 [1,0,0,0]이 됩니다.)
○ RNN의 장기의존성(Long-Ternm-Denpendency) 문제점
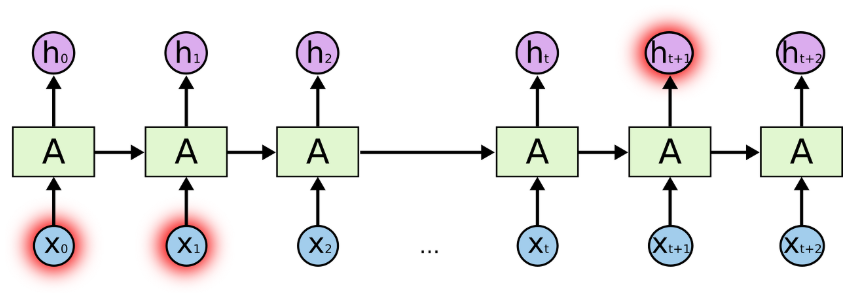
만약 "하늘에 떠있는 구름"이라는 문장을 RNN이 학습한다면 "하늘에 떠있는"이라는 문장만 가지고도 "구름"이라는 단어가 유추가 가능할 것입니다. 제공된 데이터와 배워야할 데이터의 차이가 크지 않기 때문에 과거 데이터 기반으로 학습을 할 수 있는 것입니다. 그러나 "나는 한국에서 자랐고 나는 한국어를 유창하게 한다." 라는 문장이 있을때, "나는 한국에서 자랐고 나는 ---를 유창하게 한다"에서 ---부분을 예측해야 한다면, "나는 한국에서 자랐고"와 "나는 ---를 유창하게 한다"라는 두 문장은 문장표현의 순서상 갭이 큰 문장에 속합니다. 그래서 RNN은 두 정보의 문맥을 연결하기 힘들어집니다.
● LSTM(Long Short-Term Memory)
RNN이 가진 이 장기 의존성 문제를 해결하기 위해 다양한 RNN이 나왔고 LSTM도 그 중 하나이며, LSTM은 이를 해결할 수 있는 특별한 종류의 RNN입니다. (RNN >>> LSTM) RNN이 지난 몇년간 음성인식, 언어모델링, 번역, 이미지 캡셔닝 등 다양한 분야에 성공적으로 적용된 것은 LSTM의 활용에 있다고 합니다.
LSTM은 오랜 기간동안 정보를 기억하는 일에서 특별한 작업 없이도 기본적으로 취하게 되는 특성이므로 장기 의존성 문제를 풀려고 특별히 열심히 노력할 필요 없이 우리는 그냥 케라스에서 LSTM의 라이브러리를 가져다 쓰면 됩니다!
LSTM의 구체적인 구조와 작동 방식을 보려면 글이 너무 길어질 것 같아 관련한 포스팅을 첨부합니다.
Google Brain의 Chiris olah가 쓴 LSTM에 관한 글을 한국어로 번역한 포스팅 입니다. 바로가기
LSTM(RNN) 소개
Recurrent Neural Network의 대표적인 LSTM 알고리즘 | 안녕하세요. 송호연입니다. 요즘.. 딥러닝에 푹 빠져있어서.. 퇴근후 RNN 공부할겸 아래 블로그 글을 한글로 번역하였습니다. 원 저작자, Google Brain의 Chris Olah의 허락을 받고 번역하였습니다. http://colah.github.io/posts/2015-08-Understanding-LSTMs/ RNN(Recurrent Neural
brunch.co.kr
간단한 예제들
구현코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
from numpy import array
from keras.models import Sequential
from keras.layers import Dense, LSTM
# 1. 데이터
x = array([[1,2,3], [2,3,4], [3,4,5], [4,5,6]])
y = array([4,5,6,7])
print('x shape : ', x.shape) # (4,3)
print('y shape : ', y.shape) # (4,)
# x y
# 123 4
# 234 5
# 345 6
# 456 7
print(x)
print('-------x reshape-----------')
x = x.reshape((x.shape[0], x.shape[1], 1)) # (4,3,1) reshape 전체 곱 수 같아야 4*3=4*3*1
print('x shape : ', x.shape)
print(x)
# x y
# [1][2][3] 4
# .....
# 2. 모델 구성
model = Sequential()
model.add(LSTM(10, activation = 'relu', input_shape=(3,1)))
# DENSE와 사용법 동일하나 input_shape=(열, 몇개씩잘라작업)
model.add(Dense(5))
model.add(Dense(1))
model.summary()
# 3. 실행
model.compile(optimizer='adam', loss='mse')
model.fit(x, y, epochs=100, batch_size=1)
x_input = array([6,7,8])
x_input = x_input.reshape((1,3,1))
yhat = model.predict(x_input)
print(yhat)
|
cs |
데이터를 reshape을 통해 3차원으로 만들어주는 이유는
LSTM의 입력으로는 3차원의 데이터가 필요하기 때문입니다. (data size, time_steps, features)
결과

LSTM의 파라미터를 계산하는 법은 Dense레이어와 다릅니다.
Param: 541 input_dim 3
params = dim(W)+dim(V)+dim(U) = n*n + kn + nm
# n - dimension of hidden layer
# k - dimension of output layer
# m - dimension of input layer
# RESULT 가중치 때문에 돌릴때마다 값이 다르다.
# 1 [[9.015453]]
# 2 [[9.045185]]
# 3 [[9.134788]]
# 4 [[9.215]]
# 5 [[8.963024]]
# 6 [[8.977299]]
# 7 [[9.069918]]
# 8 [[8.99183]]
# 9 [[9.249254]]
# 10 [[9.104127]]
오버피팅(과적합)이 일어나는 acc최고점, loss최저점은 어떻게 알 수 있을까요?
여러가지 방법 중 그 중 한가지는 callbacks를 이용한 EarlyStopping을 사용하는 것입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
from numpy import array
from keras.models import Sequential
from keras.layers import Dense, LSTM
x = array([[1,2,3], [2,3,4], [3,4,5], [4,5,6], [5,6,7],
[6,7,8], [7,8,9], [8,9,10], [9,10,11], [10,11,12],
[20,30,40], [30,40,50], [40,50,60]])
y = array([4,5,6,7,8,9,10,11,12,13,50,60,70])
print(x.shape) # (13,3)
print(y.shape) # (13,)
x = x.reshape((x.shape[0], x.shape[1], 1))
print(x.shape) # (13,3,1)
model = Sequential()
model.add(LSTM(20, activation = 'relu', input_shape=(3,1)))
model.add(Dense(5))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='loss', patience=100, mode='auto')
# loss값을 모니터해서 과적합이 생기면 100번 더 돌고 끊음
# mode=auto loss면 최저값이100번정도 반복되면 정지, acc면 최고값이 100번정도 반복되면 정지
# mode=min, mode=max
model.fit(x, y, epochs=1000, batch_size=1, verbose=2, callbacks=[early_stopping])
x_input = array([25,35,45]) # predict용
x_input = x_input.reshape((1,3,1))
yhat = model.predict(x_input)
print(yhat)
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
x_train = np.array([1,2,3,4,5,6,7,8,9,10])
y_train = np.array([1,2,3,4,5,6,7,8,9,10])
x_test = np.array([11,12,13,14,15,16,17,18,19,20])
y_test = np.array([11,12,13,14,15,16,17,18,19,20])
x_predict = np.array([21,22,23,24,25])
model = Sequential()
# model.add(Dense(10, input_dim=1, activation='relu'))
model.add(Dense(10, input_shape=(1, ), activation='relu'))
model.add(Dense(5))
model.add(Dense(5))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='loss', patience=10, mode='auto')
model.fit(x_train, y_train, epochs=1000, verbose=2, batch_size=1, callbacks=[early_stopping])
|
cs |
위의 코드는 EarlyStopping이 적용되지 않습니다.
왜냐하면, EarlyStopping의 인수인 monitor의 지표는 컴파일 할때 사용하는 loss의 지표와 같아야 합니다. 따라서 loss='acc'면 monitor='acc'로 맞춰줘야 하는 것 입니다.
LSTM을 DNN으로 구현한 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
# lstm -> dnn 좋음
# dnn -> lstm 별로 dnn은 불연속적인 데이터에 많이 사용하기 때문
# cnn -> lstm -> dnn도 가능
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, LSTM
a = np.array(range(1,11))
size = 5
def split_x(seq, size):
aaa = []
for i in range(len(seq) - size + 1):
subset = seq[i:(i+size)]
aaa.append([item for item in subset])
print(type(aaa))
return np.array(aaa)
dataset = split_x(a, size)
print('------------------')
print(dataset)
# RESULT
# size = 5
# [[ 1 2 3 4 5]
# [ 2 3 4 5 6]
# [ 3 4 5 6 7]
# [ 4 5 6 7 8]
# [ 5 6 7 8 9]
# [ 6 7 8 9 10]]
# 시계열 데이터는 y값이 없는 경우 많다.
# a로 y 만듬
x_train = dataset[:, 0:-1]
y_train = dataset[:, -1] # [:, 4]
print(x_train.shape) # (6, 4)
print(y_train.shape) # (6, )
# x_train
# [[1 2 3 4]
# [2 3 4 5]
# [3 4 5 6]
# [4 5 6 7]
# [5 6 7 8]
# [6 7 8 9]]
# y_train
# [ 5 6 7 8 9 10]
model = Sequential()
model.add(Dense(33, activation = 'relu', input_shape=(4,)))
model.add(Dense(5))
model.add(Dense(1))
# LSTM을 DNN으로 구현 가능
model.compile(optimizer='adam', loss='mse')
model.fit(x_train, y_train, epochs=100, batch_size=1, verbose=2)
x_input = np.array([7,8,9,10]) # (4,)
x_input = x_input.reshape(1,4)
yhat = model.predict(x_input)
print(yhat)
|
cs |
시계열 데이터에는 y값이 없는 경우가 많은데 들어온 데이터를 이용해 y를 만들 수 있습니다.
앞에서 LSTM레이어의 Params를 계산하는 방법이 일반 Dense레이어와 다르다고 하였는데, 이전의 기록들이 다음 레이어로 들어가기 때문에 LSTM레이어끼리 엮기 위해서는 return_sequence를 사용하여야 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# input_shape=(x, ) -> 실제 input(None, x)
# input_shape=(x, y) -> 실제 input(None, x, y)
from numpy import array
from keras.models import Sequential
from keras.layers import Dense, LSTM
x = array([[1,2,3], [2,3,4], [3,4,5], [4,5,6], [5,6,7],
[6,7,8], [7,8,9], [8,9,10], [9,10,11], [10,11,12],
[20,30,40], [30,40,50], [40,50,60]])
y = array([4,5,6,7,8,9,10,11,12,13,50,60,70])
print(x.shape) # (13,3)
print(y.shape) # (13,)
x = x.reshape((x.shape[0], x.shape[1], 1))
print(x.shape) # (13,3,1)
model = Sequential()
# model.add(LSTM(20, activation = 'relu', input_shape=(3,1))) # (None, 3, 1)
# model.add(LSTM(3)) # (None, 3) -> Value error
model.add(LSTM(10, activation = 'relu', input_shape=(3,1), return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True)) # (None, 3, 10)을 받는다
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(10, activation = 'relu', return_sequences=True))
model.add(LSTM(3)) # 마지막은 return_sequence X
# return_sequence를 쓰면 dimension이 한개 추가 되므로 다음 Dense Layer의 인풋에 3 dim이 들어가게 되므로 안씀
# LSTM 두개를 엮을 때
model.add(Dense(5))
model.add(Dense(1))
model.summary()
model.compile(optimizer='adam', loss='mse')
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='loss', patience=100, mode='auto')
model.fit(x, y, epochs=1, batch_size=1, verbose=2, callbacks=[early_stopping])
x_input = array([25,35,45]) # predict용
x_input = x_input.reshape((1,3,1))
yhat = model.predict(x_input)
print(yhat)
# LSTM을 2개 이상 많이 엮으면 좋지 않다.
|
cs |
LSTM을 사용할 때 훈련 시킨 데이터의 구간 외를 예측하는 것은 오차가 많이 발생합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
from numpy import array
from keras.models import Sequential
from keras.layers import Dense, LSTM
x = array([[1,2,3], [2,3,4], [3,4,5], [4,5,6], [5,6,7],
[6,7,8], [7,8,9], [8,9,10], [9,10,11], [10,11,12],
[20,30,40], [30,40,50], [40,50,60]])
y = array([4,5,6,7,8,9,10,11,12,13,50,60,70])
print(x.shape) # (13,3)
print(y.shape) # (13,)
x = x.reshape((x.shape[0], x.shape[1], 1))
print(x.shape) # (13,3,1)
model = Sequential()
model.add(LSTM(200, activation = 'relu', input_shape=(3,1)))
model.add(Dense(10))
model.add(Dense(100))
model.add(Dense(10))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit(x, y, epochs=200, batch_size=1)
x_input = array([25,35,45]) # predict용
x_input = x_input.reshape((1,3,1))
yhat = model.predict(x_input)
print(yhat)
|
cs |
이럴때 필요한 것이 Scaler인데요, 데이터의 범위를 맞춰주는 것입니다. 여러가지 Scale 기법에 대해서는 다음장에 포스팅 하도록 하겠습니다.
관련 실전 튜토리얼들
char-RNN에 대해 익힐 수 있는 예제 : 셰익스피어의 희곡을 학습하여 새로운 희곡 스타일의 문자생성
sherjilozair/char-rnn-tensorflow
Multi-layer Recurrent Neural Networks (LSTM, RNN) for character-level language models in Python using Tensorflow - sherjilozair/char-rnn-tensorflow
github.com
Hvass-Labs/TensorFlow-Tutorials
TensorFlow Tutorials with YouTube Videos. Contribute to Hvass-Labs/TensorFlow-Tutorials development by creating an account on GitHub.
github.com
과거 주가 데이터로 다음날 종가 예측 RNN (김성훈 교수님)
hunkim/DeepLearningZeroToAll
TensorFlow Basic Tutorial Labs. Contribute to hunkim/DeepLearningZeroToAll development by creating an account on GitHub.
github.com
소중한 공감 감사합니다