AI 개발
[Keras] 튜토리얼9 - MLP(MultiLayer Perceptron) 구현하기
- -
● 신경망(Neural Network)의 발전
단층 신경망 : 입력층 + 출력층
다층 신경망 : 입력층 + 히든층 + 출력층
심층 신경망 : 입력층 + 2개이상의 히든층 + 출력층
● MLP(MultiLayer Perceptron) 다층 퍼셉트론 이란?
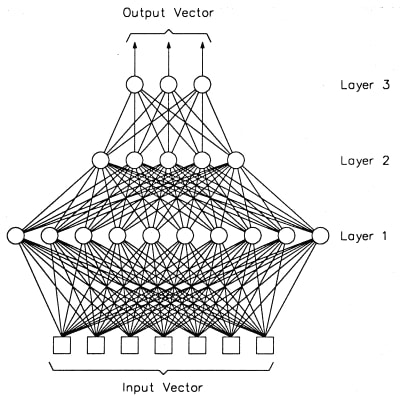
퍼셉트론으로 이루어진 층(layer) 여러 개를 순차적으로 붙여놓은 형태입니다. 입력에 가까운 층을 아래에 있다고 하고, 출력에 가까운 층을 위에 있다고 합니다. 신호는 아래에서 위로 계속 움직이며, MLP에서는 인접한 층의 퍼셉트론간의 연결은 있어도 같은 층의 퍼셉트론끼리의 연결은 없습니다. 또, 한번 지나간 층으로 다시 연결되는 피드백(feedback)도 없습니다. 각 층은 그래프 구조에서 하나의 노드처럼 동작합니다. 즉, 입력이 들어오면 연산을 한 후 출력을 내보냅니다. 대부분의 라이브러리들이 층을 구현의 최소 단위로 삼는 이유이기도 합니다. MLP는 층의 갯수(depth)와 각 층의 크기(width)로 결정됩니다. (출처)
○ MLP의 역사
인간이 생각하고 학습하는 방법을 인공지능이 흉내내기 위해 인공신경망이란 개념을 만들어냈고 이를 실현하기 위해 인간의 뉴런을 퍼셉트론으로 흉내를 내서 그 목적을 실현하려 했습니다. 하지만 인간이 생각하기에는 간단한 XOR문제처럼 선형 문제가 아닌 비선형 문제는 해결을 못하는 난관에 봉착했고, 이를 해결하기 위한 시도에서 다층 퍼셉트론(MLP)이 등장하였다고 합니다.
퍼셉트론 여러개를 가지고 몇몇 층을 쌓아서 XOR 및 단순 퍼셉트론으론 해결할 수 없는 여러 복잡한 문제들을 비로소 해결할 수 있게 되었다고 합니다. 단층 퍼셉트론을 두개 연결시켜 구성하면 비선형인 XOR문제도 해결할 수 있습니다.
○ MLP의 문제점
그러나 이렇게 다층으로 퍼셉트론을 쌓아 XOR문제 및 여러 복잡한 문제를 해결할 것만 같았던 다층 퍼셉트론에도 문제가 하나 있었습니다. Oupput Layer의 Target value가 있는 것과 달리 중간의 Hidden Layer가 가지고 있는 node에는 Target Value가 존재하지 않아 학습을 시킬 방법이 없었던 것입니다. 즉, 은닉층의 오차(목표값과 실측값의 차이)를 구하기 난해했다는 것 입니다. 실측값은 계산하면 되지만 목표값은 출력단에서 알 수 있어서 적용을 어떻게 시켜야 하는지 난해했던 것입니다.
또, MLP를 사용하려면 은닉층(히든레이어)를 늘려야하는데 그 과정에서 또 다른 문제가 발생합니다. 바로 Overfitting문제와 Vanishing Gradient 문제 입니다.
- Overfitting :
트레이닝 셋에 너무 과최적화되어 실제 데이터를 집어 넣어 분류를 하려고 하면 정확도가 좀 떨어지는 것
- Vanishing Gradient :
layer가 deep해지면서 backpropagation으로 에러를 뒤로 전파하게 되는데에 문제가 생긴것. 경사하강법을 통해 에러에 대한 값을 새로운 w에 업데이팅 시켜줘야 하는데 각각의 레이어를 계속 거치면서 계속 경사하강법을 통해 미분하고 미분하고 하다보니 뒤로 전해지면서 에러값이 현저히 작아져 학습이 제대로 안됨
○ MLP문제점 해결
위와 같은 문제를 해결하기 위해 딥러닝은 이와 같은 방법을 사용합니다.
- Overfitting
: Regularization(weight가 너무 커버리지 않게 조절),
More training data(Validation set을 활용 정확도를 조절),
Reduce the nuber of features
- Vanishing Gradient
: 활성화 함수를 변경(ex. Sigmoid 함수 -> ReLU함수)
구현 코드_1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
# 1. 데이터
import numpy as np
x = np.array([range(1,101), range(101,201)]) # 데이터가 두개!
y = np.array([range(1,101), range(101,201)])
print(x)
print(x.shape) # (2,100) 2행 100열
x = np.transpose(x)
y = np.transpose(y)
print(x.shape) # (100,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
# 2. 모델 구성
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(10, input_shape=(2, ), activation='relu'))
model.add(Dense(10))
model.add(Dense(8))
model.add(Dense(2)) # input col 2개 이므로 output도 2개
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val))
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
y_predict = model.predict(x_test)
print(y_predict)
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
|
cs |
위 코드가 앞의 튜토리얼 예제 코드와 다른점은,
x = np.array([range(1,101), range(101,201)])
y = np.array([range(1,101), range(101,201)])
x데이터와 y데이터 즉, 입력데이터와 출력데이터가 2개로 구성되어있다는 것입니다. 예를 들어 (공부시간, 공부량) 데이터를 넣어 (점수, 등수)를 예측할때, 사용할 수 있는 모델입니다.
model.add(Dense(10, input_shape=(2, ), activation='relu')) # input_shape(2)
.....
model.add(Dense(2)) # output(2)
위와 같이 인풋데이터와 아웃데이터의 shape만 잘 맞춰주면 모델은 돌아갑니다. 다량의 실제데이터를 사용한다면 하이퍼파라미터 튜닝을 더 잘해주어야 합니다.
예를 들어 (삼성주가, sk주가) 데이터를 넣고 (종합주가)를 예측하는 모델을 만들고 싶다!
그러면 x1, x2데이터를 입력으로 넣고 y데이터를 출력으로 정하고 shape을 맞춰줍니다.
x = np.array( [ [~~~], [~~~] ] )
y = np.array([~~~])
model.add(Dense(10, input_shape=(2, ), activation='relu')) # input_shape(2)
.....
model.add(Dense(1)) # output(1)
구현 코드_2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
# aaa라는 임의의 데이터를 구성한 모델로 예측 (오류가 있는 문제)
# 1. 데이터
import numpy as np
x = np.array([range(1,101), range(101,201)])
y = np.array([range(201,301)])
# print(x)
# print(x.shape) # (2,100) 2행 100열
x = np.transpose(x)
y = np.transpose(y)
# print(x.shape) # (100,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
# 2. 모델 구성
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(50, input_shape=(2,), activation='relu'))
model.add(Dense(10))
model.add(Dense(10))
model.add(Dense(1))
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val))
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
aaa = np.array([range(101,104), range(201,204)])
aaa = np.transpose(aaa)
y_predict = model.predict(aaa)
print(y_predict)
y_train = y[:70]
y_val = y[70:97]
y_test = y[97:]
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
|
cs |
문제 : 위 코드의 문제점은 무엇일까요?
더보기
정답
구현코드_1에서 예측하는 부분의 코드는 y_predict = model.predict(x_test) 입니다. 즉, 원본 데이터의 일부분인 테스트 데이터 셋으로 y값을 예측하는 것입니다. 하지만 쿠현코드_2의 부분을 보면,
aaa = np.array([range(101,104), range(201,204)])
aaa = np.transpose(aaa)
y_predict = model.predict(aaa)
print(y_predict)
원본 데이터셋에 포함된 데이터가 아닌 새로운 데이터를 생성하였습니다. 즉 y의 train, val, test의 갯수를 조작해서 실행은 할 수 있지만, 새로 생성한 데이터 aaa의 test 값이 없으므로 aaa를 예측한다는 자체가 오류가 있는 것입니다.
'AI 개발' 카테고리의 다른 글
| [Keras] 튜토리얼 11 - LSTM(feat. RNN) 구현하기 (2) | 2020.01.04 |
|---|---|
| [Keras] 튜토리얼10 - 앙상블(ensemble) (1) | 2019.12.31 |
| [Anaconda] 개발환경 설치 및 WIN32 응용프로그램 오류 (3) | 2019.12.27 |
| [Keras] 튜토리얼8 - 함수형으로 모델 구축(functional API) (1) | 2019.12.21 |
| [Keras] 튜토리얼7 - 데이터 자르기(train_test_split) (1) | 2019.12.20 |
Contents
소중한 공감 감사합니다