AI 개발
[Keras] 튜토리얼14(마지막) - 모델 SAVE, LOAD, Tensorboard 이용하기

새로운 언어나 프레임워크를 배울 때, 예전에는 두꺼운 책을 하나 사서 1장부터 공부 -> 예제 따라하기 이런식으로 공부를 했었는데요. 그렇게 되면 1장만 열심히 하고 뒤로 갈 수록 공부를 안하게 되더라구요..... 저만 그렇나요?
그렇게 기초부터 하나씩 익혀가면 물론 좋겠지만, 사람의 기억력이라는 것이 원래 복습을 안하면 공부한 것에 10%만 남는다고 하잖아요? 그래서 프로그래밍을 아예 모르는 사람이 아니라면 새로운 언어나 프레임워크를 배울 때, 거기에 관련된 개념들의 대표 예제를 먼저 따라해본 후 개념을 대충 익히는 식으로 공부하는 것이 훨씬 효율적이라고 생각합니다. 나중에 실전 프로그래밍을 할 때 비슷한 개념이 나오면 다시 찾아볼때 복습한다고 생각하면서 공부하면 처음부터 두꺼운 책을 공부하는 것과 별로 다를게 없더라구요!
그렇게 해서 포스팅 하게 된 것이 무작정 튜토리얼 시리즈 인데요. 오늘 드디어 마지막 포스팅을 업로드 하고 다음 포스팅 부터는 회귀문제와 분류문제와 같은 실전 문제를 코딩하며 다시 개념을 복습하는 예제를 올리려고 합니다!
무작정 튜토리얼 시리즈의 마지막 편은 만든 모델을 저장하고, 불러오는 법과 텐서보드를 이용해 학습 수치를 시각화 하는 법을 살펴보도록 하겠습니다.
○ MODEL SAVE
케라스 MLP 예제코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
# 1. 데이터
import numpy as np
x = np.array([range(1,101), range(101,201)])
y = np.array([range(1,101), range(101,201)])
print(x)
print(x.shape) # (2,100) 2행 100열
x = np.transpose(x)
y = np.transpose(y)
print(x.shape) # (100,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
# 2. 모델 구성
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(10, input_shape=(2, ), activation='relu'))
model.add(Dense(10))
model.add(Dense(8))
model.add(Dense(2)) # input col 2개 이므로 output도 2개
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val))
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
y_predict = model.predict(x_test)
print(y_predict)
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
|
cs |
지난 포스팅에서 다뤘던 MLP모델을 만들고 학습하고 평가를 예측하는 코드인데요,
이렇게 데이터를 학습시키기 위해 만든 모델을 실행시킬때, 수천건의 데이터와 몇 십개의 레이어와 천번 이상의 epochs를 돌려야하는 모델이라면 결과가 나오는데 꽤 시간이 걸릴 것입니다.
이렇게 딥러닝 모델을 사용할 때마다 매번 오랜 시간에 걸려 학습시켜야 할까요?
정답은 아니오! 입니다. 이미 학습된 모델의 가중치를 저장하여 그와 관련한 데이터를 예측할 때 학습을 또 시키지 않고 저장된 가중치를 적용하여 결과를 바로 볼 수 있습니다.
실무에서의 딥러닝 시스템

우리가 만들고자 하는 전체 시스템을 목표 시스템이라고 했을 때, 크게 ‘학습 segment’와 ‘판정 segment’로 나누어집니다.
학습 segment
: 학습은 학습을 위해, 학습 데이터를 얻기 위한 ‘학습용 센싱 element’, 센싱 데이터에서 학습에 적합한 형태로 전처리를 수행하는 ‘데이터셋 생성 element’, 그리고 데이터셋으로 딥러닝 모델을 학습시키는 ‘딥러닝 모델 학습 element’으로 나누어집니다.
판정 segment
: 판정은 실무 환경에서 수집되는 센서인 ‘판정용 센싱 element’과 학습된 딥러닝 모델을 이용해서 센싱 데이터를 판정하는 ‘딥러닝 모델 판정 element’으로 나누어집니다. 앞서 본 코드에는 딥러닝 모델 학습 element와 딥러닝 모델 판정 element가 모두 포함되어 있습니다. 이 두 가지 element를 분리해보겠습니다.
model.save('mlp_model.h5')
모델을 저장(학습된 가중치를 저장) 하는 방법은 매우 간단합니다. save()함수를 이용하여 딱 한줄만 추가해주면 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# 1. 데이터
import numpy as np
x = np.array([range(1,101), range(101,201)])
y = np.array([range(1,101), range(101,201)])
print(x)
print(x.shape) # (2,100) 2행 100열
x = np.transpose(x)
y = np.transpose(y)
print(x.shape) # (100,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
# 2. 모델 구성
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(10, input_shape=(2, ), activation='relu'))
model.add(Dense(10))
model.add(Dense(8))
model.add(Dense(2)) # input col 2개 이므로 output도 2개
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val))
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
y_predict = model.predict(x_test)
print(y_predict)
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
## 모델 SAVE ##
from keras.models import load_model
model.save('mlp_model.h5')
|
cs |
그러면 현재 디렉토리 안에 mlp_model.h5라는 파일이 생성됩니다.
이 파일에는 다음과 같은 정보들이 담겨 있습니다.
- 나중에 모델을 재구성하기 위한 모델의 구성 정보
- 모델를 구성하는 각 뉴런들의 가중치
- 손실함수, 최적하기 등의 학습 설정
- 재학습을 할 수 있도록 마지막 학습 상태
모델 Architecture 확인
model_to_dat() 함수를 통해 모델 아키텍처를 가시화 시킬 수 있습니다. model 객체를 생성한 뒤라면 언제든지 아래 코드를 호출하여 모델 아키텍처를 블록 형태로 볼 수 있습니다.
|
1
2
3
4
5
6
|
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
%matplotlib inline
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
|
cs |
결과
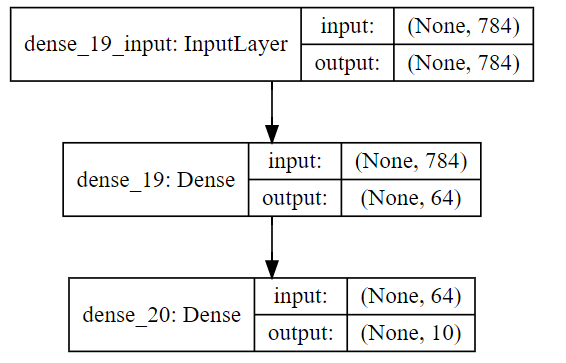
○ MODEL LOAD
학습된 모델의 가중치를 이용하여 predict()를 하기 위해서 저장한 모델을 불러 옵니다. 주로 실제 예측을 위해 predict()를 사용하지만 Sequential 기반의 분류 모델을 사용할 경우 predict_classes()를 사용할 수 있고 이는 가장 확률이 높은 클래스 인덱스를 알려줍니다. Functional API기반의 모델은 다수개의 입출력으로 구성된 다양한 모델을 구성할 수 있기 때문에 예측함수의 출력 형태 또한 다양합니다. 따라서 클래스 인덱스를 알려주는 간단한 예측함수는 Functional API 모델에서는 제공하지 않습니다.
model = load_model('mlp_model.h5')
모델을 불러오는 방법도 매우 간단합니다. 모델을 구성하는 부분을 load_model()함수 한 줄로 대체해주면 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
# 1. 데이터
import numpy as np
x = np.array([range(1,101), range(101,201)])
y = np.array([range(1,101), range(101,201)])
print(x)
print(x.shape) # (2,100) 2행 100열
x = np.transpose(x)
y = np.transpose(y)
print(x.shape) # (100,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
## 모델 LOAD ##
from keras.models import load_model
model = load_model('mlp_model.h5')
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val))
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
y_predict = model.predict(x_test)
print(y_predict)
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
|
cs |
모델 구조와 가중치를 따로 저장하기
모델 아키텍처는 model.to_json() 함수와 model.to_yaml() 함수를 이용하면 json 혹은 yaml 형식의 파일로 저장할 수 있습니다. 가중치는 model.save_weights() 함수로 파일 경로를 인자로 입력하면 h5 형식의 가중치 파일이 생성됩니다. 따로 저장한 경우에는 구성 시에도 따로 해야 합니다. 모델 아키텍처를 먼저 구성한 뒤 가중치를 불러와서 모델에 셋팅하면 됩니다.
|
1
2
3
4
5
6
7
|
from models import model_from_json
json_string = model.to_json() # 모델 아키텍처를 json 형식으로 저장
model = model_from_json(json_string) # json 파일에서 모델 아키텍처 재구성
from models import model_from_yaml
yaml_string = model.to_yaml() # 모델 아키텍처를 yaml 형식으로 저장
model = model_from_yaml(yaml_string) # yaml 파일에서 모델 아키텍처 재구성
|
cs |
저장된 파일에는 모델 구성 및 가중치 정보외에도 학습 설정 및 상태가 저장되므로 모델을 불러온 후 재 학습을 시킬 수 있습니다. 신규 데이터셋이 계속 발생하는 경우에는 재학습 및 평가가 빈번하게 일어날 수 있습니다. 또한 일반적인 딥러닝 시스템에서는 학습 처리 시간을 단축시키기 위해 GPU나 클러스터 장비에서 학습 과정이 이루어지나, 판정 과정은 학습된 모델 결과 파일을 이용하여 일반 PC 및 모바일, 임베디드 등에서 이루어집니다. 이처럼 도메인, 사용 목적 등에 따라 운영 시나리오 및 환경이 다양하기 때문에, 딥러닝 모델에 대한 연구도 중요하지만, 실무에 적용하기 위해서는 목표 시스템에 대한 설계도 중요합니다.
○ TENSORBOARD 사용하기
케라스에서 만든 모델의 수치들로 제대로 학습이 되고 있는지 중단할지 등을 결정하게 됩니다. 이 수치들을 매 에포크마다 바뀌는 변화추이를 쉽게 살펴보기 위해 그래프를 이용하게 됩니다. 그래프로 수치들을 시각화 하는 tensorboard라는 기능을 케라스에서는 제공하고 있습니다.
텐서보드를 사용하지 않고도 히스토리 기능을 사용하여 loss, acc, val_loss, val_acc 값 들을 객체화해 히스토리를 얻을 수도 있습니다.
|
1
2
3
4
5
6
|
hist = model.fit(X_train, Y_train, epochs=1000, batch_size=10, validation_data=(X_val, Y_val))
print(hist.history['loss'])
print(hist.history['acc'])
print(hist.history['val_loss'])
print(hist.history['val_acc'])
|
cs |
결과
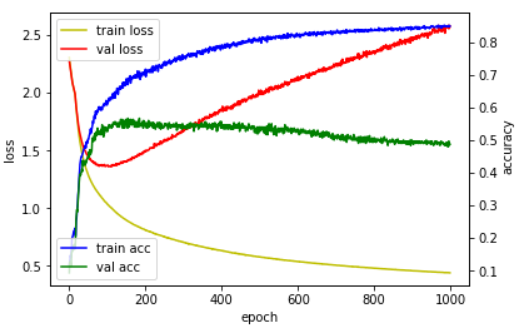
tb_hist = TensorBoard(log_dir='graph', histogram_freq=0, write_grads=True, write_images=True)
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val), callbacks=[early_stopping, tb_hist])
텐서보드를 사용하는 법도 모델 save, load 못지 않게 매우 간단합니다. 딱 2줄만 추가해주면 됩니다. 단, 케라스의 백엔드가 텐서플로우일때만 사용가능합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
# 1. 데이터
import numpy as np
x = np.array(range(1,101)) # 1~100
y = np.array(range(1,101))
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=66, test_size=0.4)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, random_state=66, test_size=0.5)
# 2. 모델 구성
from keras.models import Sequential
from keras.layers import Dense, BatchNormalization, Dropout
model = Sequential()
model.add(Dense(10, input_shape=(1,), activation='relu'))
model.add(Dense(5))
model.add(Dense(3))
model.add(Dense(1))
# 3. 훈련
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
# tensorboard
from keras.callbacks import EarlyStopping, TensorBoard
tb_hist = TensorBoard(log_dir='graph', histogram_freq=0, write_grads=True, write_images=True) # graph 디렉토리 생성해주기
early_stopping = EarlyStopping(monitor='loss', patience=30, mode='auto')
model.fit(x_train, y_train, epochs=100, batch_size=1, validation_data=(x_val, y_val),
callbacks=[early_stopping, tb_hist])
# 4. 평가 예측
loss, mse = model.evaluate(x_test, y_test, batch_size=1)
print('acc : ', mse)
y_predict = model.predict(x_test)
print(y_predict)
# RMSE 구하기
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE : ', RMSE(y_test, y_predict))
# R2 구하기
from sklearn.metrics import r2_score
r2_y_predict = r2_score(y_test, y_predict)
print('R2 : ', r2_y_predict)
|
cs |
코드를 실행 시킨 뒤, cmd창을 열어 텐서보드를 실행시켜줍니다.
>> tensorboard --logdir=logs(로그가 저장되어 있는 폴더명)
그리고 실행창에 뜬 페이지에 접속하여 줍니다. https://localhost:6006
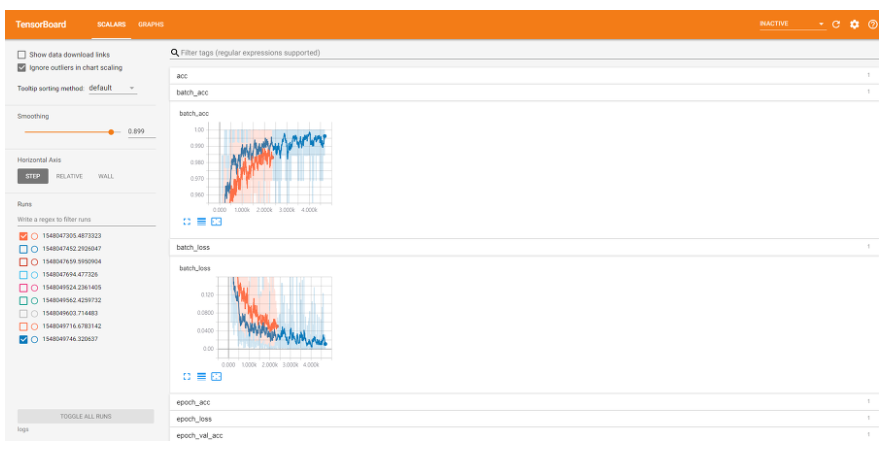
이제부터 접속한 페이지에서 텐서보드를 통해 매 에포크마다의 acc, loss 값등의 변화 추이를 살펴볼 수 있습니다.
'AI 개발' 카테고리의 다른 글
| [캐글] 중고차 가격 예측 모델2_Gradient Boost, Random Forest (3) | 2020.01.16 |
|---|---|
| [캐글] 중고차 가격 예측 모델1_선형회귀 Linear Regression() (37) | 2020.01.16 |
| [Keras] 튜토리얼13 - CNN(Convolution Neural Network) (0) | 2020.01.08 |
| [Keras] 튜토리얼12 - Scikit-learn의 Scaler (0) | 2020.01.05 |
| [Keras] 튜토리얼 11 - LSTM(feat. RNN) 구현하기 (2) | 2020.01.04 |
Contents
소중한 공감 감사합니다