AI 개발
[캐글] 중고차 가격 예측 모델1_선형회귀 Linear Regression()
● Kaggle

캐글(Kaggle)은 머신러닝 대회로 유명한 플랫폼 입니다. 알고리즘 문제를 푸는 백준, 프로그래머스 사이트와 비슷한 개념입니다. 캐글에 있는 여러 데이터셋과 문제들로 데이터 전처리, 모델 설계, 하이퍼파라미터 선택과 튜닝에 대해 익힐 수 있습니다. 경쟁자가 제출한 코드를 볼 수도 있고 다른 경쟁자에 비해 내가 얼마나 잘 풀었는지 확인해 볼 수도 있습니다.
현재 활성화 되고 있는 도전 과제를 풀어 볼 수도 있고, 머신러닝 입문 문제로 유명한 타이타닉 생존자 예측문제, 보스턴 주택 가격문제 등에 대한 데이터셋을 다운 받을 수도 있고 잘 푼사람들의 코드를 보면서 머신러닝 문제의 개념을 익힐 수도 있습니다.
● 중고차 가격 예측 문제 풀어보기
실전 문제를 풀면서 머신러닝에 대한 감을 익히기 위해 캐글에 있는 데이터 셋을 가져와서 중고차 가격을 예측하는 문제를 풀어보려고 합니다. 캐글에 있는 대회 데이터는 학습셋과 테스트셋으로 나누어져 있기도 하고 전처리가 잘 되어 있는 형태가 많아서 귀찮은 전처리 과정 없이 바로 문제를 풀 수 있습니다.
데이터셋 다운
test-data.csv
0.12MB
train-data.csv
0.63MB
1. 데이터셋 읽고 구조 확인

먼저 필요한 라이브러리들을 임포트 시켜줍니다.
csv파일의 전처리에 유용한 pandas, 데이터 시각화에 이용할 matplotlib, 머신러닝 라이브러리인 sklearn등을 임포트 하였습니다.

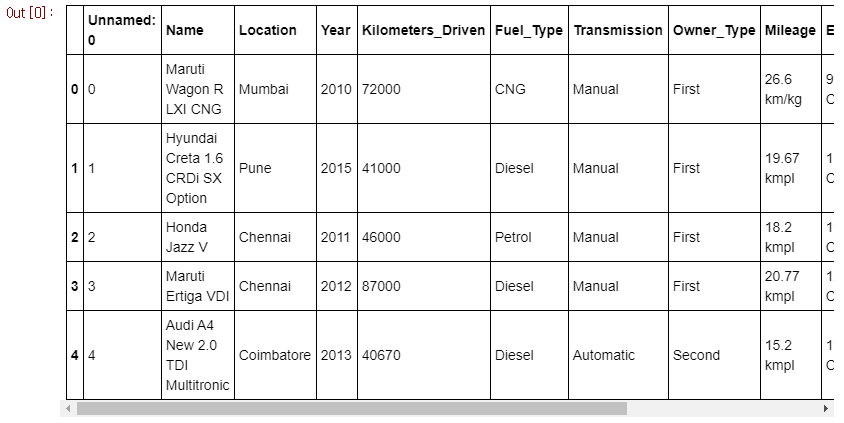
dummy_data 라는 변수에 csv 파일을 불러오고 구조를 확인합니다. 저는 colab을 사용하였기 때문에 경로가 저렇고 파일을 저장한 경로를 넣어주면 됩니다.
데이터의 row, col 수를 알아보기 위해 shape()을 사용합니다.
print('row 수 : {}, col 수 : {}'.format(dummy_data.shape[0], dummy_data.shape[1]))>> row 수 : 6019, col 수 : 14
자동차의 모델, 연식, 킬로미터수, 연료타입 등을 활용하여 가격을 예측해보려고 합니다. 앞선 포스팅에서 종속변수(여기서는 가격)이 독립변수(모델, 연식, 킬로수....등등)에 따라 어떻게 변하는지 살펴보는 것이 회귀모델이라고 하였습니다.
참고 2019/12/22 - [SW개발/AI Keras] - [딥러닝] 선형회귀와 로지스틱회귀
그래서 우리는 회귀모델을 이용하여 컬럼들의 속성으로 가격을 예측하는 모델을 만들어보도록 하겠습니다.
2. 데이터 전처리

데이터를 전처리 할 때, 가장 먼저 하는 일 중에 하나는 NaN(결측치)를 확인하고 제거하는 일입니다. NaN을 제거할 때 데이터의 속성을 잘 확인하여야 합니다. 만약 데이터가 수치 값이라면 NaN에 평균값을 넣어주는 등의 처리를 할 수도 있지만 위치, 이름 등과 같이 어떤 값으로 대체하기 어렵다면 결측치가 있는 row를 아예 제거하기도 합니다.
위의 데이터에서 결측치를 제거하였더니 6019개였던 행의 수가 813개가 되어버리므로 데이터의 손실이 너무 많아지게 됩니다. 그리고 head()를 이용하여 데이터의 헤더를 살펴보면 New_Price의 값에 NaN이 굉장히 많다는 것을 확인 할 수 있습니다. 그래서 New_Price 컬럼 값을 제거하였습니다. 또 Unnamed:0 컬럼도 인덱스를 부여하는 것외에 정보가 없기 때문에 제거하였습니다.
두개의 컬럼을 제거하고 NaN을 가진 행을 제거하니 6019개의 로우가 5975개가 되었습니다. 나쁘지 않은 데이터 수 입니다.

차의 모델명을 가진 컬럼은 Name컬럼인데, Name컬럼의 도메인이 몇개인지 확인하기 위해 unique()를 사용하였습니다. 자동차 모델의 종류는 총 1855가지나 됩니다. 이는 자칫 오버피팅을 초래할 수도 있기 때문에 차종의 Hyundai Creta 1.6 CRDi SX Option과 같은 이름을 Hyundai 등의 브랜드만 남기고 제거하였습니다. 31 종류의 차종이 남았습니다.

그리고 Mileage컬럼,Engine컬럼,Power컬럼은 km/kg와 CC, bhp등의 단위를 가지고 있습니다. 데이터의 단위를 제거하고 수치만 남겨놓았습니다.
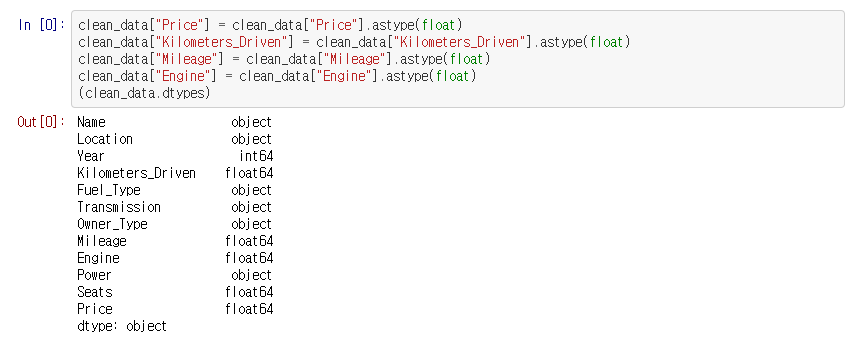
각 컬럼의 데이터형 확인
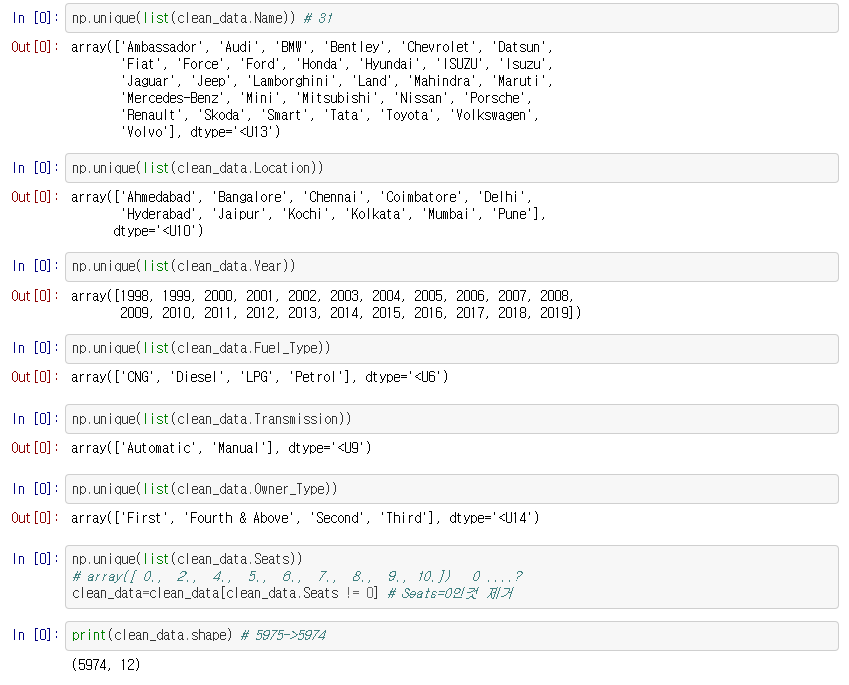
각 컬럼들의 도메인을 확인하다가 Seats컬럼에서 좌석의 수가 0인 데이터가 있었는데 이를 제거하였습니다.
그리고 데이터 프레임에서 .isnull().sum() 함수를 이용해 확인 할 때는 null 값이 없다고 나왔는데 Power컬럼에 null값이 있었습니다.. 이에 대해 아시는 분은 댓글 부탁드립니다. ㅜㅜ

아무튼 그래서 Power컬럼의 null을 제거하고 각 컬럼들을 카테고리컬로 분류하여 데이터 프레임을 재정의 하였습니다. (One-hot encoding)
Name 컬럼의 종류가 Hyundai, Audi, BMW....이런식으로 있으면 컬럼을 Name_Hyundai, Name_Audi, Name_BMW...이런식으로 나누어 데이터프레임을 재정의하는 것입니다.

그랫더니 총 79개의 컬럼이 생성되었습니다!

이상치(Outlier)를 확인하기 위해 matplot을 이용해 그래프를 그려봅니다. Kilometers Driven컬럼을 보면 하나의 값이 유독 너무 큰 값이 있습니다.
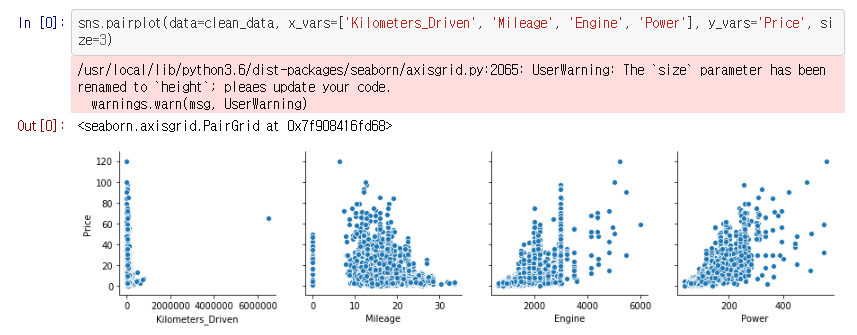

이를 제거해보았습니다.
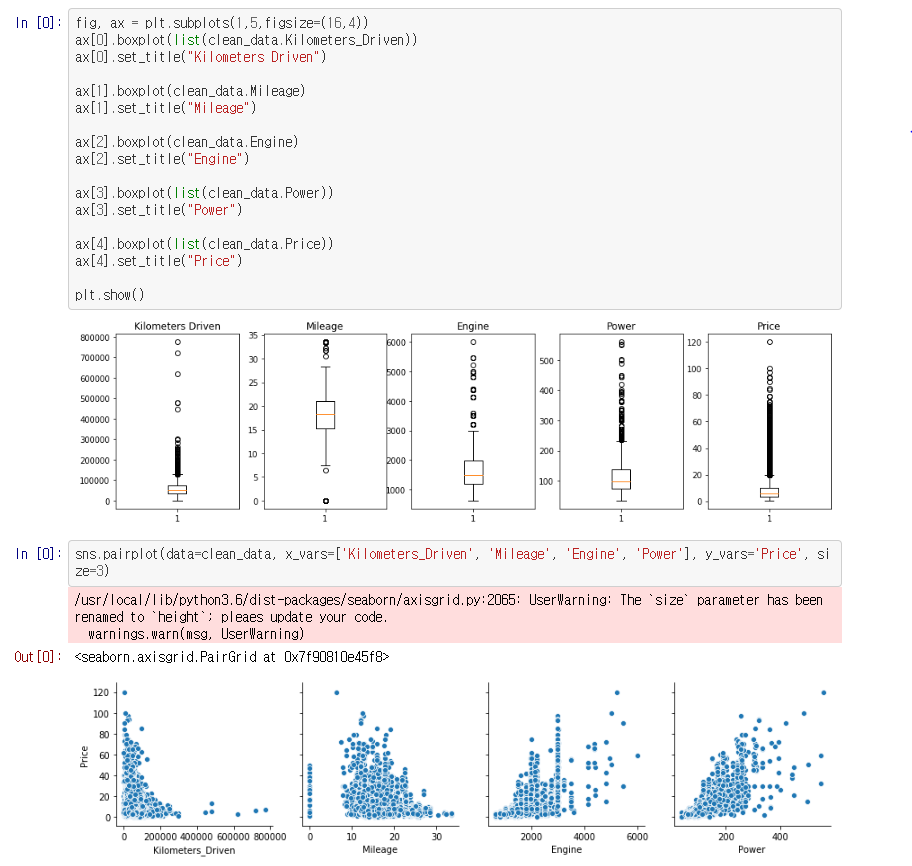
그랬더니 튀는 아웃라이어가 없는 그래프가 그려졌습니다.
3. 데이터셋 생성
데이터에 훈련, 테스트 셋이 나누어져 있었는데 전처리를 train셋만 가지고 하였기 때문에 훈련셋의 15퍼센트를 테스트셋에 사용하였습니다.
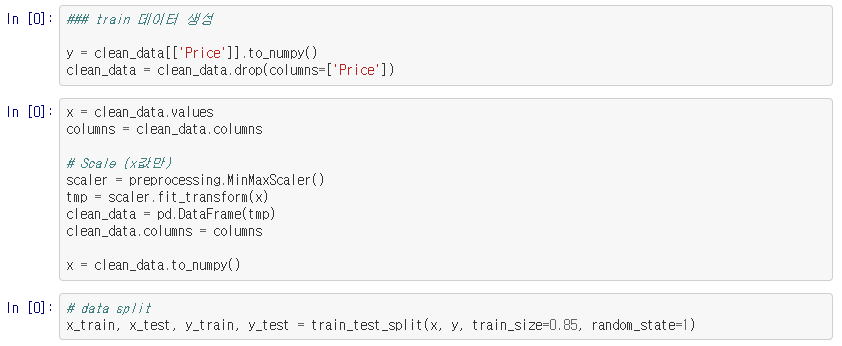
4. 모델링

sklearn에서 제공하는 선형회귀 함수를 사용하여 모델링을하고 트레이닝(fit)시킵니다.
5. 결과 확인
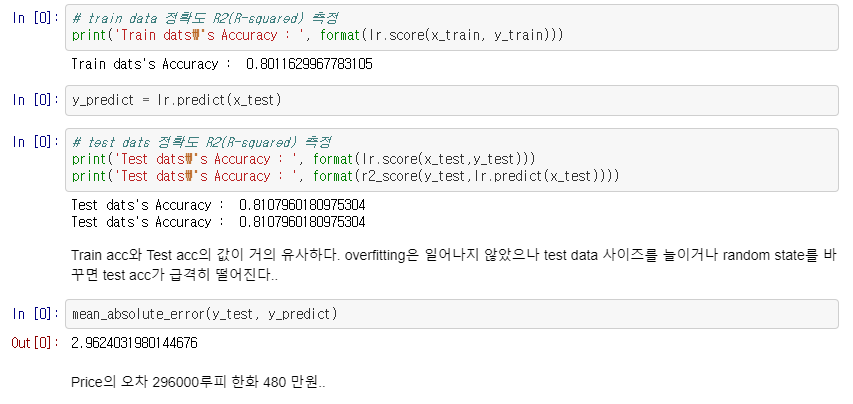
인도의 자동차 가격 데이터 인가봅니다... 오차가 약 480만원정도 나왔습니다. 다음 포스팅에서는 gradient_boost모델과 랜덤포레스트 모델을 적용하여 이 오차를 줄여보겠습니다!
편의상 colab에서 작성한 코드를 캡쳐하여 첨부하였습니다.
코드를 다운받거나 folk하시려면 아래 깃허브주소에서 받아주세요 STAR 도 눌러주세요@@
github.com/MinkyungPark/usedcar-price-predict
'AI 개발' 카테고리의 다른 글
| [KoNLPy] 자연어 처리1 - KoNLPy로 데이터 전처리 (0) | 2020.01.28 |
|---|---|
| [캐글] 중고차 가격 예측 모델2_Gradient Boost, Random Forest (3) | 2020.01.16 |
| [Keras] 튜토리얼14(마지막) - 모델 SAVE, LOAD, Tensorboard 이용하기 (0) | 2020.01.12 |
| [Keras] 튜토리얼13 - CNN(Convolution Neural Network) (0) | 2020.01.08 |
| [Keras] 튜토리얼12 - Scikit-learn의 Scaler (0) | 2020.01.05 |
Contents
소중한 공감 감사합니다