AI 개발
[Gensim] 자연어 처리3 - Gensim의 Word2Vec으로 토픽모델링
● Word2Vec

언어 모델링을 할 때, 언어(텍스트)를 신호 공간에 매핑(숫자로)하는 부분은 필수적입니다. 이러한 전처리를 단어 임베딩(Word Embedding)이라고 하는데 자연어 처리의 가장 기초적인 단계이며 현재까지 여러 방식이 제안되어 왔습니다.
이러한 임베딩 방식에서 가장 기초적인 방법은 '원 핫 인코딩(One-hot Encoding)'인데, ['강아지', '고양이', '동물', '멍멍이', '반려견']이라는 단어집합이 있을 때, 강아지 -> 1, 멍멍이 ->4 이런식으로 단어를 숫자에 그냥 무작정 매핑하는 방식입니다. 이렇게 만들어진 원핫벡터는 단어간 의미도와 유사도 등을 전혀 반영하지 못하게 됩니다. 언어끼리의 유사도나 의미를 반영한 벡터로 언어 모델을 구성하였을 때가 텍스트 분류나 NER 등 다른 자연어 task 모델에서 더 좋은 성능을 내는 것은 당연하겠죠?
Word2Vec은 언어의 의미와 유사도를 고려하여 언어를 벡터로 매핑하는 방식을 사용하는 패키지 중 하나이며 오늘은 Gensim의 Word2Vec 패키지에 대해 알아보도록 하겠습니다.
gensim word2vec
: 단어마다 차례대로 인덱싱을 하여 벡터화 하지 않고, 유사한 단어들을 비슷한 방향과 힘의 벡터를 갖도록 단어를 벡터화 시켜주는 방법 중 하나이다.
word2vec으로 단어들을 임베딩 시키면 단어끼리 연산이 가능합니다. 예를 들어, '고양이 + 애교 = 강아지' 라던가 '한국 - 서울 + 도쿄 = 일본' 과 같이요. 이렇게 단어간 연산이 가능하려면 단어의 벡터는 '의미'를 가지고 있어야 한다는 뜻이 됩니다. 어떻게 word2vec은 이런식으로 단어를 벡터화 하는 것이 가능한지 살펴보도록 하겠습니다.
그 이전에, 먼저 단어의 표현 방법들에 대해서 알아봐야 합니다.
단어의 표현 방법 1 : 희소 표현(Sparse Representation)
앞서 원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 벡터 표현 방법이었습니다. 이렇게 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 합니다. 그러니까 원-핫 벡터는 희소 벡터(sparse vector)입니다.
단어의 표현 방법 2 : 분산 표현(Distributed Representation)
희소 표현은 각 단어간 유사성을 표현할 수 없다는 단점이 있었고, 이를 위한 대안으로 단어의 '의미'를 다차원 공간에 벡터화하는 방법을 찾게되는데, 이러한 표현 방법을 분산 표현(distributed representation)이라고 합니다. 그리고 이렇게 분산 표현을 이용하여 단어의 유사도를 벡터화하는 작업은 워드 임베딩(embedding) 작업에 속하기 때문에 이렇게 표현된 벡터 또한 임베딩 벡터(embedding vector)라고 하며, 저차원을 가지므로 밀집 벡터(dense vector)에도 속합니다.
분산 표현방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법입니다. 이 가정은 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정입니다. 강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 저런 내용을 가진 텍스트를 벡터화한다면 저 단어들은 의미적으로 가까운 단어가 됩니다. 분산 표현은 분포 가설을 이용하여 단어들의 셋을 학습하고, 벡터에 단어의 의미를 여러 차원에 분산하여 표현합니다.
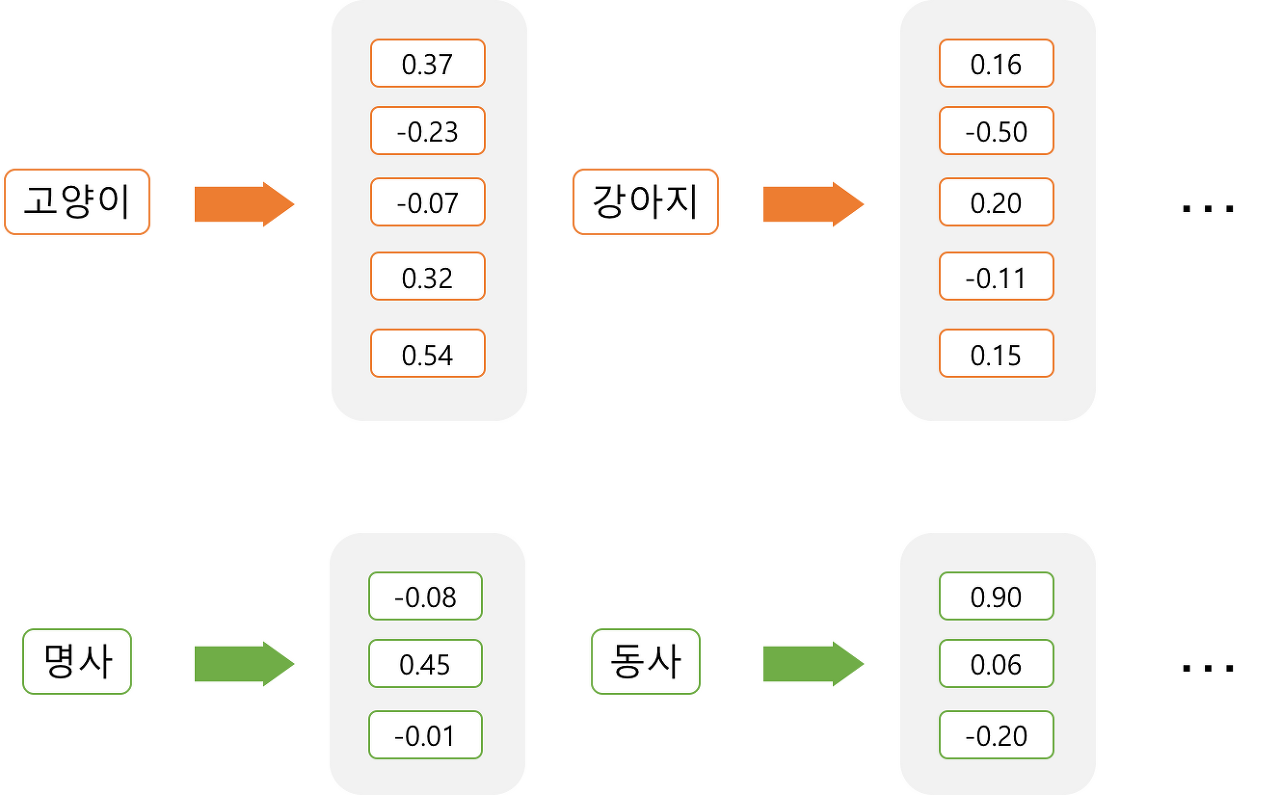
예를 들어,
강아지라는 단어를 '원-핫 벡터' 즉 희소 표현 방법으로 표현하면
강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0]
단어 집합이 10000개 였다면, 강아지 라는 단어의 벡터는 5번째 자리 이후로 0이 9995개가 있는 벡터가 됩니다. 하지만 Word2Vec으로 임베딩 된 벡터는 벡터의 차원이 단어 집합의 크기가 될 필요가 없습니다!
강아지라는 단어를 분산 표현 방법으로 표현하면
강아지 = [0.2 0.3 0.5 0.7 0.2 ... 중략 ... 0.2]
Word2Vec으로 임베딩 된 벡터는 사용자가 설정한 차원을 가지는 벡터가 되면서 각 차원은 실수형의 값을 가지게 됩니다.
요약하면 희소 표현이 고차원에 각 차원이 분리된 표현 방법이었다면, 분산 표현은 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현합니다. 이런 표현 방법을 사용하면 단어 간 유사도를 계산할 수 있습니다.
그리고 이를 위한 학습 방법 중 하나가 Word2Vec 인 것입니다.
● Word2Vec의 두 가지 방식
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다. CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법입니다. 반대로, Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법입니다.
1. CBOW(Continuous Bag of Words)
예를 들어 '우리집 강아지는 공을 정말 좋아한다.' 라는 문장에서 '공' 부분을 맞춘다면, '우리집', '강아지', '는', '을', '정말', '좋아', '한다' 의 단어들을 가지고 '공'을 예측해야 합니다. 이 때 예측해야 하는 단어 '공'이 중심 단어(center word)이고, 나머지 단어들을 주변 단어(context word)라고 합니다.
중심 단어를 예측하기 위해 앞, 뒤로 몇 개의 단어를 볼 지 정하는데 이 범위를 '윈도우(window)'라고 합니다. 예를 들어 윈도우 크기를 2로 설정하였다면, 앞의 두 단어 '강아지', '는'과 뒤의 두 단어 '을', '정말'을 가지고 '공'을 예측하는데 사용합니다.

윈도우 크기를 정했다면, 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만들 수 있는데, 이 방법을 슬라이딩 윈도우(sliding window)라고 합니다.
2. Skip-gram
Skip-gram은 CBOW를 이해했다면, 메커니즘 자체는 동일하기 때문에 쉽게 이해할 수 있습니다. 앞서 CBOW에서는 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측하려고 합니다.
여러 논문에서 성능 비교를 진행했을 때, 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있습니다.
● word2vec 실습
데이터 다운로드
: 'GoogleNews-vectors-negative300.bin'
https://github.com/mmihaltz/word2vec-GoogleNews-vectors
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
# 단어와 2차원 X축의 값, Y축의 값을 입력받아 2차원 그래프를 그린다
def plot_2d_graph(vocabs, xs, ys):
plt.figure(figsize=(8 ,6))
plt.scatter(xs, ys, marker = 'o')
for i, v in enumerate(vocabs):
plt.annotate(v, xy=(xs[i], ys[i]))
sentences = [
['this', 'is', 'a', 'good', 'product'],
['it', 'is', 'a', 'excellent', 'product'],
['it', 'is', 'a', 'bad', 'product'],
['that', 'is', 'the', 'worst', 'product']
]
# 문장을 이용하여 단어와 벡터를 생성한다.
model = Word2Vec(sentences, size=300, window=3, min_count=1, workers=1)
# 단어벡터를 구한다.
word_vectors = model.wv
vocabs = word_vectors.vocab.keys()
word_vectors_list = [word_vectors[v] for v in vocabs]
# 결과1 : 단어간 유사도를 확인
print(word_vectors.similarity(w1='it', w2='this'))
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
xys = pca.fit_transform(word_vectors_list)
xs = xys[:,0]
ys = xys[:,1]
# 결과2
plot_2d_graph(vocabs, xs, ys)
file_name = 'GoogleNews-vectors-negative300.bin'
model.intersect_word2vec_format(fname=file_name, binary=True)
# 단어벡터를 구한다.
word_vectors = model.wv
vocabs = word_vectors.vocab.keys()
word_vectors_list = [word_vectors[v] for v in vocabs]
# 결과3 :단어간 유사도를 확인하다
print(word_vectors.similarity(w1='it', w2='this'))
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
xys = pca.fit_transform(word_vectors_list)
xs = xys[:,0]
ys = xys[:,1]
# 결과4
plot_2d_graph(vocabs, xs, ys)
# 최종 모델을 저장한다.
model.save('word2vec.model')
# 저장한 모델을 읽어서 이용한다.
model = Word2Vec.load('word2vec.model')
|
cs |
- 결과1
-0.22223482
- 결과2

- 결과3
0.53861594
- 결과4

결과를 살펴보면, 결과2에서는 'this' 단어와 'it' 단어의 거리가 먼 것으로 보아 두 단어간 유사도가 반영되지 않았다고 볼 수 있습니다. 하지만 결과4에서 미리 학습한 모델과 병합을 하니 'this'와 'it' 단어의 유사도 만큼 두 단어의 거리는 가깝고, 'worst'와 'excellent' 두 단어는 반대의 의미를 가진 만큼 두 단어의 거리가 멀게 나타났습니다!
한국어 pre-trained word2vec model 다운로드는 여기
● word2vec의 파라미터

- 맨 앞, sentences는 학습시킬 문장을 입력합니다.
- workers : 실행할 병렬 프로세스의 수, 코어수, 주로 4-6사이 지정
- size : 각 단어에 대한 임베딩 된 벡터차원 정의, size=2라면 한 문장의 벡터는 [-0.1248574, 0.255778]와 같은 형태를 가지게 된다.
- min_count : 단어에 대한 최소 빈도수. min_count=5라면 빈도수 5 이하 무시
- window : 문맥 윈도우 수, 양쪽으로 몇 개의 단어까지 고려해서 의미를 파악할 것인지 지정하는 것
- sample : 빠른 학습을 위해 정답 단어 라벨에 대한 다운샘플링 비율을 지정하는 것, 보통 0.001이 좋은 성능을 낸다고 한다.
- sg : 1이면 skip-gram 방법을 사용하고, 0이면 CBOW 방법을 사용한다.
- iter : epoch와 같은 뜻으로 학습 반복 횟수를 지정한다.
이렇게 생성된 word2vec 모델은 문장 내 각 토큰들(단어들)끼리의 의미를 고려하여 구조화된 벡터를 가지는 쪽으로 학습하여 단어들을 벡터로 바꾸어 줍니다. 이렇게 생성된 벡터를 가지고 Embedding레이어에 적용하여 NLP task를 수행할 수 있습니다.
word2vec을 사용하는 방법까지 알아보았으니,
- KoNLPy로 데이터를 전처리,
- NLTK로 데이터를 탐색,
- word2vec으로 토픽 모델링(문장 내 규칙, 토픽을 찾음)
을 통해 언어모델을 만들고 NLP task를 수행하는 여러 모델의 성능을 높여봅시다.
자연어처리를 위한 파이썬 패키지 시리즈
KoNLPy 데이터 전처리
2020/01/28 - [SW개발/Framework Library] - [파이썬패키지] 자연어 처리를 위한 패키지1 - KoNLPy로 데이터 전처리
NLTK 데이터 탐색
2020/01/31 - [SW개발/Framework Library] - [파이썬패키지] 자연어 처리를 위한 패키지2 - NLTK로 데이터 탐색
Gensim 토픽 모델링
2020/02/17 - [SW개발/Framework Library] - [파이썬패키지] 자연어 처리를 위한 패키지3 - Gensim의 Word2Vec으로 토픽모델링
References
한국어 단어 임베딩을 위한 Word2vec 모델의 최적화
wevi : word embedding visual inspector
한국어와 NLTK, Gensim의 만남 (Lucy Park)
'AI 개발' 카테고리의 다른 글
| [Numpy] 딥러닝을 위한 Numpy1 - Numpy기초 (0) | 2020.03.05 |
|---|---|
| [Keras] Embedding Layer에 word2vec 주입하기 (4) | 2020.02.21 |
| [Python] lambda, map, filter, reduce (0) | 2020.02.05 |
| [NLTK] 자연어 처리2 - NLTK로 데이터 탐색 (0) | 2020.01.31 |
| [KoNLPy] 자연어 처리1 - KoNLPy로 데이터 전처리 (0) | 2020.01.28 |
Contents
소중한 공감 감사합니다