SW 개발
[알고리즘] 순열, 조합, 그래프 표현 _ 파이썬
▒ 코딩테스트 공부 방법
1. codeup 기초 100제로 기초를 다지고 사용할 언어에 익숙해지도록 한다.
2. 백준온라인 저지 단계별, 유형별 문제를 푼다.
배열, 문자열, 정렬, 브루트포스(완전탐색), 재귀, 백트래킹, 동적계획법, bfs/dfs 등의 유형에 익숙해진다.
-완전탐색(재귀나 백트래킹으로)->시뮬레이션->그래프(위상정렬, 다익스트라..)->최소신장유니온트리(유니온파인드 등)->심화문제(스택으로 라인스위핑 같은)->DP, dp는 코딩테스트에 나오면 완죠니 어렵게 나온다고 한다.
3. 프로그래머스 코딩테스트 고득점 kit를 푼다.
유형별 4~7문제를 풀며 자주 나오는 유형을 익힌다.
4. 프로그래머스 스킬체크
주어진 시간내에 2문제를 풀고, 나의 실력을 파악한다. 레벨3정도면 웬만한 코딩테스트에 합격할 수 있다고 한다.
오늘 공부해 볼 내용은
1. 순열과 조합
파이썬의 itertools.permutations, .combinations 사용하면 쉽게 풀 수 있다.
○ 순열
: 서로다른 n개의 원소에서 r개를 뽑는 모든 경우의 수. 중복 허용하지 않고(순서고려) 순서대로 늘어놓은 것. nPr
- 일반적인 방법
def permute(arr):
result = [arr[:]]
c = [0] * len(arr)
i = 0
while i < len(arr):
if c[i] < i:
if i % 2 == 0:
arr[0], arr[i] = arr[i], arr[0]
else:
arr[c[i]], arr[i] = arr[i], arr[c[i]]
result.append(arr[:])
c[i] += 1
i = 0
else:
c[i] = 0
i += 1
return result
- itertools.permutation 이용
import itertools
pool = ['A', 'B', 'C']
print(list(map(''.join, itertools.permutations(pool)))) # 3개의 원소로 수열 만들기
print(list(map(''.join, itertools.permutations(pool, 2)))) # 2개의 원소로 수열 만들기
- 재귀를 이용한 방법
def perm(lis, n):
result = []
if n > len(lis): return result
if n == 1:
for li in lis:
result.append([li])
elif n > 1:
for i in range(len(lis)):
tmp = [i for i in lis]
tmp.remove(lis[i])
for j in perm(tmp, n-1):
result.append([lis[i]]+j)
return result
n = int(input())
lis = list(i for i in range(1, n+1))
for li in perm(lis,n):
print(' '.join(list(map(str, li))))
bfs/dfs 를 이용할 수도 있다.
○ 조합
: 서로다른 n개의 원소에서 r개를 뽑는 모든 경우의 수. 중복을 허용한(순서고려X) nCr
사용방법은 순열과 동일하다.
2. 파이썬으로 그래프 표현하기
dfs, bfs 문제를 풀 때 처음에 연결된 노드와 간선을 자료구조로 표현해야 하는데,
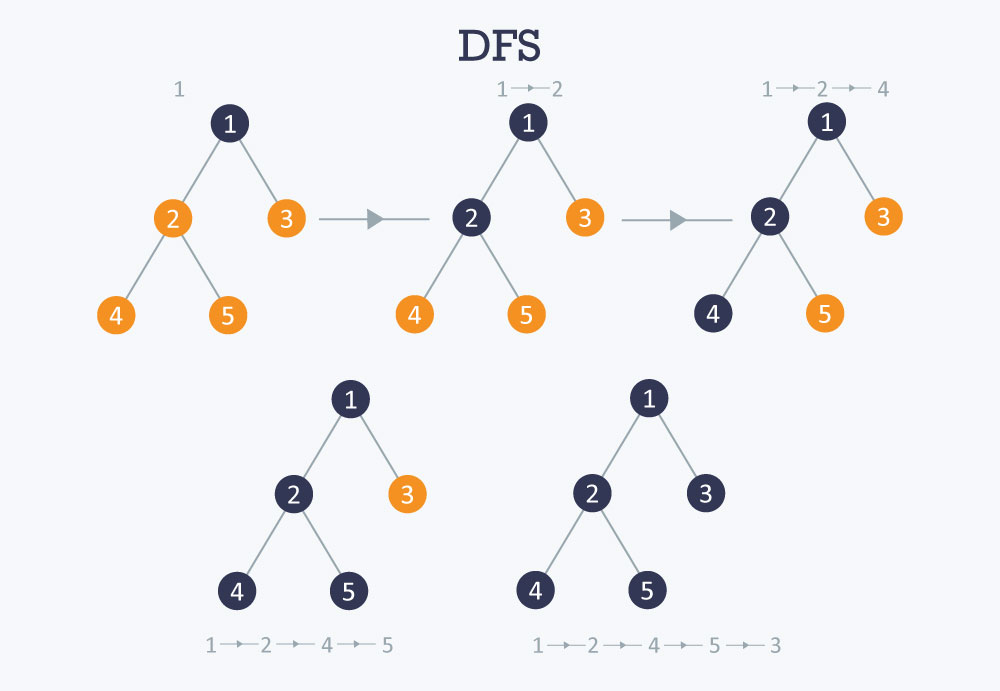
이런 DFS문제를 풀어야 할 때 저 그래프를 어떻게 파이썬으로 표현할 수 있을까요
크게 두 가지 방법이 있습니다.
1. 인접리스트(Adjacency list)
2. 인접행렬(Adjacency matrix)
저는 bfs, dfs 문제를 풀 때 보통 인접행렬을 많이 사용했는데요. 파이썬의 2차원 리스트를 사용해 만들 수 있습니다.
1) 인접행렬
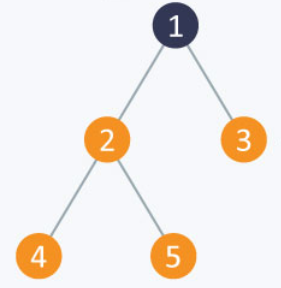
이런 그래프의 인접행렬은
| Node_Num | 0 | 1 | 2 | 3 | 4 | 5 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 1 | 1 |
| 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 | 0 |
다음과 같습니다. 이를 파이썬 리스트로 표현한다면,
s = [[0]*6 for i in range(6)]
s[1][2] = 1
s[2][1] = 1
s[1][3] = 1
s[3][1] = 1
s[2][4] = 1
s[4][2] = 1
s[2][5] = 1
s[5][2] = 1위와 같이 코드를 작성 할 수 있습니다. 노드의 개수가 5개인데 6*6으로 초기화 한 이유는 인덱스를 노드번호 그대로 사용하기 위해서 이렇게 했고 5*5로 지정해주고 인덱싱할때 Node_num - 1 해주셔도 됩니다.
하지만 노드의 개수에 비해 간선(엣지)의 개수가 훨씬 적다면, 인접행렬보단 인접리스트를 사용하는 것이 탐색에 효율적입니다. 연결된 노드의 수만큼만 살펴보면 되고 메모리도 간선 수만큼만 차지하기 때문입니다. 하지만 두 노드의 연결 관계를 알고싶다면 인접 행렬이 효율적입니다.
2) 인접리스트
아까와 똑같은 그래프를 인접 리스트로 표현해 보겠습니다. 이 경우 노드가 5개이고 간선이 4개 이므로 인접 리스트를 사용하는 것이 효율적일 것입니다. 이때 이용하는 것이 파이썬의 set타입인데, set은 집합 자료형으로 중복을 허용하지 않고, 순서가 없으며 따라서 인덱싱이 되지 않습니다. 딕셔너리({})와 비슷하지만 차이점은 Key값이 없다는 점입니다. 값만 존재합니다.
adj_list = {1: set([2,3]),
2: set([1,4,5]),
3: set([1]),
4: set([2]),
5: set([2])}
set 내부 원소는 다양한 값을 함께 가질 수 있지만, mutable 한 값은 가질 수 없습니다. mutable은 값이 변할 수 있는것이고 immutable은 값이 변하지 않는 것입니다. immutable에는 Number, String, Tuple이 있고 mutable에는 List, Dictionary가 있습니다.
3. BFS, DFS
- BFS 너비우선 탐색

말 그대로 너비가 넓어지는 방식으로 탐색을 하는 방법입니다. 시작노드에서 부터 인접한 노드를 큐에 넣는 방법을 사용합니다. 모든 노드를 적어도 한번은 방문합니다.
def bfs(graph, start):
visited = []
queue = [start]
while queue:
n = queue.pop(0)
if n not in visited:
visited.append(n)
queue += graph[n] - set(visited)
return visited
큐의 .append와 .pop을 이용해 bfs를 구현하는데, pop()은 시간 복잡도가 O(N)이며,
좀 더 효율적으로 사용하고 싶으면 collections의 dequeue를 사용하면 시간을 절약할 수 있습니다.
dequeue는 double-ended queue의 줄임말이고, 양방향에서 데이터를 처리할 수 있는 자료구조 입니다.
- Python의 deque 이용
from collections import deque
def bfs_dequeue(graph, start):
visited = []
queue = deque([start])
while queue:
n = queue.popleft()
if n not in visited:
visited.append(n)
queue += graph[n] - set(visited)
return visited
또는 실제 Queue처럼 동작하는 파이썬의 Queue를 사용해도 됩니다.
- Python의 Queue()이용
from queue import Queue
def bfs_queue(graph, start):
visited = []
q = Queue()
q.put(start)
while q.qsize() > 0:
n = q.get()
if n not in visited:
visited.append(n)
for adj in graph[n]:
q.put(adj)
return visited
※ 참고
if n not in visited 에서 visited부분은 리스트로 구현이 되어 있습니다. 따라서 이부분을 탐색하는 시간이 O(N)이 소요가 되는데요. 그러면 굳이 deque와 Queue()를 이용한 보람이 없겠죠. 그래서 visited를 딕셔너리나, set을 이용하는 것이 시간을 줄여준다고 합니다. 기존의 딕셔너리와 set은 순서를 보존하지 않았지만 3.7 이상부터는 딕셔너리가 순서를 보존하도록 바뀌었다고 하니 딕셔너리({})를 사용하면 될 것 같습니다. 아직 set은 순서보존이 되지 않는다고 합니다.
- visited 를 딕셔너리로
def bfs_queue(graph, start):
visited = {}
q = Queue()
q.put(start)
while q.qsize() > 0:
n = q.get()
if n not in visited:
visited[n] = True
for adj in graph[n]:
q.put(adj)
return list(visited.keys())
- visited 를 set()으로
def bfs_queue(graph, start):
visited = set()
q = Queue()
q.put(start)
while q.qsize() > 0:
n = q.get()
if n not in visited:
visited.add(n)
for adj in graph[n]:
q.put(adj)
return visited
출력시, 리스트가 아닌 요소만 출력하고 싶다면,
result = bfs_queue(adj_list,1)
print(' '.join(list(map(str, result))))
- DFS 깊이 우선 탐색

말 그대로 시작 노드에서 부터 깊이가 가장 깊은 곳까지 노드를 쭉 방문 하고 이전 위치로 돌아와 다시 가장 깊은 노드까지 쭉 방문하는 탐색 방법입니다. 트리 순회 기법은 모두 이 DFS를 사용합니다. 스택을 통해 구현하거나 재귀를 이용합니다.
def dfs(graph, start):
visited = []
stack = [start]
while stack:
n = stack.pop()
if n not in visited:
visited.append(n)
stack += graph[n] - set(visited)
return visited
위와 같은 그래프를 위 코드로 돌리면 경로가 1,3,2,5,4 로 출력되는데(같은 깊이 일 때 오른쪽부터 순회) , 만약 1, 2, 4, 5, 3 이렇게(같은 깊이일 때 왼쪽부터 순회) 출력하고 싶다면 stack에 n의 인접 노드를 추가하는 부분을 반대로 되게 해주어야 합니다.
현재 탐색하고 있는 노드가 1번이라고 하였을 때,(n=1) stack에 2,3을 넣어주게 되면 스택은 맨 뒷부분을 pop하기 때문에 visited에는 1->3으로 출력되기 때문이죠. 따라서 저 단계에서 stack에 3,2 순으로 넣어주어야 합니다. 스택에 넣어주는 부분을 간단하게 stack += reversed(graph[n]) - set(visited)를 해주면 되지만.. 맨 처음에 그래프를 set으로 구현해놓았기 때문에 reversed가 안됩니다. 그래서 이 경우는 처음에 graph의 딕셔너리의 value값을 리스트로 해주면 됩니다.# set을 유지하면서 반대 방향으로 스택에 넣는 방법을 아시는 분 알려주세요..
모든 노드를 방문하는 방법 말고, 시작노드와 발견해야하는 노드가 정해져 있을 때 즉 두 노드간 경로를 탐색 할 때는 위의 코드들을 조금 수정하면 됩니다.
- 두 노드간 모든 경로_BFS
def bfs_paths(graph, start, end):
queue = [(start, [start])]
result = []
while queue:
n, path = queue.pop(0)
if n == end:
result.append(path)
else:
for m in graph[n] - set(path):
queue.append((m, path+[m]))
return result
- 두 노드간 모든 경로_DFS
def dfs_paths(graph, start, end):
result = []
stack = [(start,[start])]
while stack:
n, path = stack.pop()
if n == end:
result.append(path)
else:
for m in graph[n] - set(path):
stack.append((m, path+[m]))
return result
※ set 사용시 순서를 유지하면서 어떻게 중복 제거?
References
http://ejklike.github.io/2018/01/05/bfs-and-dfs.html
https://www.hackerearth.com/practice/algorithms/graphs/depth-first-search/tutorial/
'SW 개발' 카테고리의 다른 글
| [알고리즘] 완전탐색 문제풀이 _ 파이썬 (0) | 2020.10.06 |
|---|---|
| [알고리즘] BFS/DFS 문제 풀이 _ 파이썬 (0) | 2020.09.10 |
| [NodeJS] 자바스크립트 비동기 연산을 다루는 Promise (0) | 2020.08.26 |
| [Docker] Docker로 서버 구축(feat. node.js, 귀여운 도커템) (1) | 2020.06.26 |
| [Docker] Windows Docker와 Virtual Box (0) | 2020.06.26 |
Contents
소중한 공감 감사합니다