인공지능 AI
[RL] Behavior Transformers: Cloning k modes with one stone
Behavior Transformers: Cloning k modes with one stone
Link : https://arxiv.org/pdf/2206.11251.pdf
Abstract
behavior learning은 인상적인 발전을 보여주었지만, 아직 large scale의 human-generated dataset을 활용하지 못하기 때문에 비전이나 자연어처리 분야만큼의 발전을 이루진 않았다. Human behavior는 넓은 분산과 다중 모드를 가지고 있고 human demonstration데이터셋은 일반적으로 reward가 label되어 있지 않다. 이러한 속성은 현재 큰 스케일의 pre-collected dataset을 활용해서 offline RL과 Behavior Cloning(BC)에 적용하기에는 한계가 있다. 따라서 해당 논문에서는 다중 모드를 가지면서 라벨링이 되어 있지 않은 deomonstration dataset을 모델링 하는 새로운 테크닉, Behavior Transformer(BeT)를 소개한다. BeT는 Object detection에서 offset prediction에 영감을 받아 multi-task action correction을 action discretization에 결합하여 기존 Transformer에 장착한다. 이는 multi-modal continuous action을 예측하기 위한 모던 트랜스포머의 multi-model modeling ability를 이용할 수 있게 해준다.
Introduction
RL에서 behavior learning의 성공은 높은 샘플 복잡성을 필요로 한다. 어떻게 행동하는지에 대한 사전 지식이 없는 최신 RL 방식은 벤치마크 제어 작업을 위해 100만에서 1000만 개의 리워드가 라벨링된 샘플에 대한 온라인 상호작용을 필요로 한다. 이는 nlp, vision 에서 pretrained model이나 data-driven prior을 사용하는 것이 표준이 되어 효율적인 다운스트림 태스크를 해결할 수 있는 것과 대조적이다.
그래서 해당 논문에서는 다음과 같은 물음을 제시한다. "how do we learn behavioral priors from pre-collected data?" 수집된 데이터로부터 behavior prior을 어떻게 학습할 수 있을까?. 하나의 옵션은 offline RL이다. conservative policy optimization과 결합된 offline dataset로 task-specific behavior을 학습할 수 있다. 그러나 이 방법은 아직 task-specific reward 라벨이 없는 경우는 다루지 못했다. explicit reward label 없이는, imitation learning, 특히 behavior cloning가 더 적합한 옵션이다. Behavior model은, demostration 데이터셋이 충분할 때, state, action페어의 데이터셋이 주어졌을 때 supervised learning을 통해 state를 받고 action을 예측하는 방식으로 학습된다.(f(s)->a). 이는 self-driving부터 robotic manipulation까지 다양한 도메인에서 인상적인 성공을 보였다. 그리고 특히 이 접근법이 좋은 이유는 온라인 상호작용이나 리워드 라벨이 필요 없다는 점이다.
그러나 최신 BC 메소드는 single task를 해결하는 unimodal expert로부터 만들어진 데이터를 가져온다는 기본적인 가정을 하는 경우가 많다. 이러한 가정은 가우시안 prior를 사용하는 등 아키텍쳐 설계에 내장되어 있는 경우가 많다. 반면 사전에 수집된 natural 데이터셋은 sub-optimal이고, 노으지가 많으며 다중 behavior mode가 하나의 데이터셋에 얽혀 있다. 이러한 분산 multi-modal experience는 human demostration에서 가장 두드러진다. 우리는 매일 매우 다양한 행동을 할 뿐 아니라 personal bias로 인해 같은 행동이라고 해도 다양한 양상(multi-modality)를 보인다. 최근 BC에 관한 접근법은, 중요하게 goal-conditioned policy에 초점을 맞추고 있다. 각 goal은 hehavior의 단일 모드를 암시하고 있다. 그러나 goal-conditioning 후에도 여전히 "multi-modal behavior dataset을 기본적으로 'clone(복제)'할 수 있는 모델을 학습하려면 어떻게 해야하는지"에 대한 중요한 질문이 남아 있다.
해당 논문에서는, 풍부하고 multi-modal 분포를 지닌 데이터셋으로 부터 behavior을 러닝하기 위한 새로운 방법인 BeT(Behavior Transformer)을 제시한다. BeT는 3개의 키 인사이트를 지니고 있다.
- 트랜스포머 베이스의 시퀀스 모델의 multi-token prediction을 기반으로 한 context를 이용한다.
- 트랜스포머는 자연스럽게 discrete class를 예측하는데 적합하므로, 저자들은 continous action을 k-means를 사용해서 discrete bin로 클러스터링 한다. 이는 고차원의 연속 multi-modal action distribution을 카테고리컬 분포로 복잡한 생성모델을 학습하지 않고 모델링할 수 있게 한다.
- BeT로부터 샘플된 액션이 online rollout에 유용하게 하기 위해 샘플링된 action bin에 대해 continuous action을 생성하기 위해 residual action corrector를 동시에 학습한다.

BeT는 one mode로 collapsing되거나 latching되지 않고, training behavior dataset에 존재하는 주요 mode를 모두 포괄할 수 있으며 BeT로부터 unconditional rollout(goal conditioning을 안한다는 의미인듯?)하는 그림은 위 figure를 통해 확인할 수 있다.
Behavior Transformers
우리가 관심있는 behavior가포함된 continuous observation, action pair의 데이터셋 D={(o,a)}가 주어졌을 때, 우리의 목표는 behavior policy \pi: O -> A 를 학습하는 것이고 어떠한 온라인 상호작용이나 리워드 라벨 없이 모델링한다.
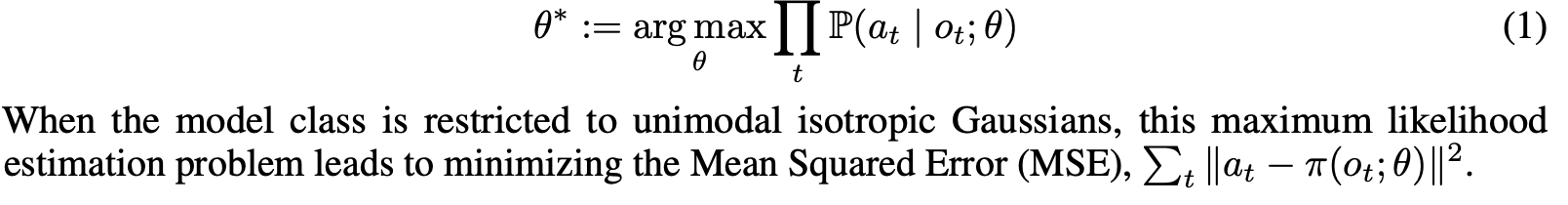
Behavior Cloning은 o_t가 주어졌을 때 a_t에 매핑되는 데이터셋의 probability를 최대화하는 parameter \theta를 찾는 방법이다. 모델 클래스가 unimodal isotropic Gaussian이라고 가정하면, 이 maximum likelihood estimation문제는 MSE(Mean Squared Error) 를 minimizing하는 것과 같다.
Limitations of traditional MSE based BC
MSE-based BC는 데이터셋 분포가 unimodal이라고 가정하는데, 특정 작업을 특정 방식으로 해결하는 cleaned expert demo 데이터셋은 이 가정을 충족하지만, 미리 수집된 intelligent behavior은 그렇지 않은 경우가 많다. 최근 Behavior generation model은 이러한 문제를 해결하기 위해 노력했지만 복잡한 generative model, exponential한 수의 액션 bin, 복잡한 training 방법, 테스트 시간 최적화를 필요로 하는 경우가 많다.
Overview of Behavior Transformer(BeT):
저자들은 regular BC의 2개의 critical 가정을 완화하는? BeT의 가정에 대해 설명한다.
- 첫째로, cloning하려는 action이 purely Markovian(현재 행동은 이전 상태에만 영향을 받는다.)를 완화하고 대신 some horizon h에 대한 확률 P(a_t|o_t, o_t+1, .. o_t-h_1)을 모델링한다.
- 두번째로, unimodal action distribution에서 action이 생성되었다고 가정하는 것 대신, mixture of gaussian으로 action 분포를 모델링한다.
하지만 이전에 Mixture Density Network(MDN)를 사용했던 것과는 달리 BeT는 model center을 명시적으로 예측하지 않으므로 모델링 능력이 크게 향상된다고 저자들은 말한다. 위 두 가정을 single behavior 모델에서 운영하기 위해, 트랜스포머를 사용하는 이유는
- 트랜스포머는 prior observation history를 활용하는데 효과적이고,
- 아키텍쳐를 통해 multi-modal token을 출력하는데 자연스럽게 적합하기 때문이다.
Action discretization for distribution learning
트랜스포머가 시퀀스 모델링에 있어 standard backbone이기는 하지만, 트랜스포머는 discrete token을 예측하기 위해 디자인 되었다. 그래서 고차원 continuous variable의 multi-modal distribution을 모델링하는 것은 challenging problem이며 특히 만약 우리가 데이터셋에 있는 mode를 나타내는 behavior model을 학습하기 위해서도 어려운 문제이다. 그래서 이를 해결하기 위해 action을 'action centor'를 나타내는 categorical variable과 이에 대응되는 'residual action'으로 나누어 action prediction task의 새로운 방식을 제안한다.

먼저 action 클래스를 k-means를 통해 나눈 다음 continuous action vector a가 주어졌을 때 action class A_i와 가장 가까운 class i로 매칭한다. 그리고 residual action은 continuous action vector a와 액션 클래스 A_i의 차이로 정의한다. 그래서 실제 액션은 Action class A_i와 residual action <a>를 더한 값이 된다.

먼저 k-means based encoder, decoder로 action factorization process를 만든 다음 train과 test 때는 이를 고정한다.
Attention-based behavior mode learning
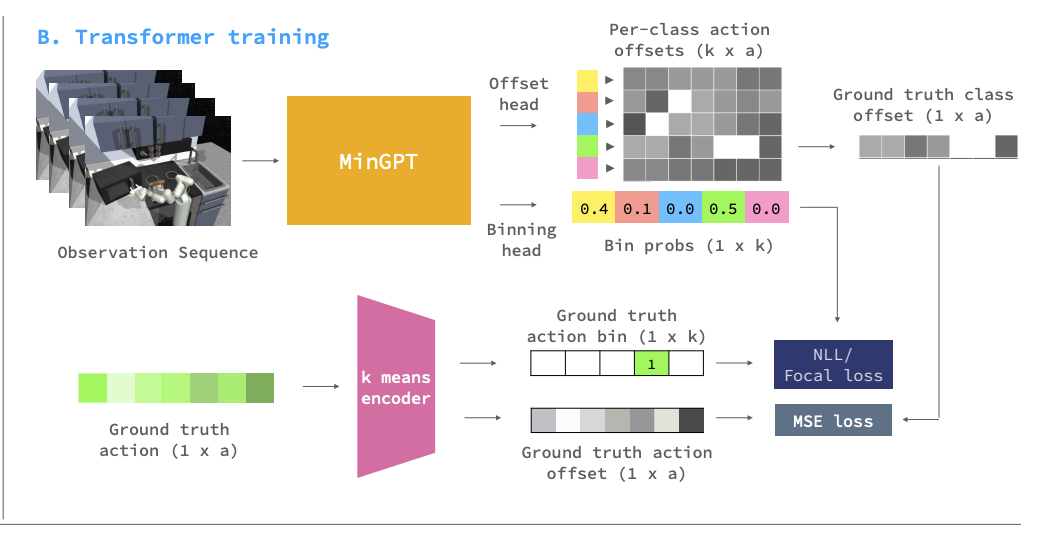
먼저 action bining을 위한 autoencoder 베이스의 클러스터링이 있을 때, demonstration trajectories를 BeT로 모델링 한다. 이때 Transformer decoder(minGPT)를 약간 수정하여 Backbone으로 사용했다. observation (o_i, o_i+1, .. o_i+h-1) 즉 h개의 observation을 받고, observation을 k discrete action bin의 categorical distribution으로 매핑하기 위한 sequence-to-sequence model을 러닝한다. 이때 true action label 분포와 predicted action label 분포의 loss를 계산하기 위해 negative-log-likelihood-based Focal loss를 사용했다고 한다. Focal loss는 cross entropy loss를 간단하게 수정한 objective이고 binary classification cross entropy가 -log(p)라면 그 앞에 (1-p)^\gamma 텀을 곱해준 것이다.
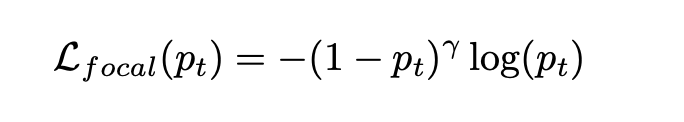
이 loss는 p_t 값이 작을 수록 gradient가 가파르며 p_t가 클수록 기울기가 평평해지는 흥미로운 특징을 가지고 있다. 따라서 낮은 확률 클래스에서 오류가 발생하면 더 많은 불이익을 주고 모델을 변경하는 반면, 높은 확률 클래스에서 오류가 발생하면 더 관대하다는 특성이 있다. object detection에서 배경은 높은 확률로 object가 아님이 잘 구분 되지만, 이미지에서 object 영역보다 background 영역이 훨씬 많다. 즉 배경 부분같은 중요하지 않은 영역은 loss가 작아도 그 비율이 많아 전체 gradient를 계산할 때 중요하지 않은 영역의 영향이 커지는 것을 방지하기 위해 고안 된 loss이다.(https://arxiv.org/pdf/1708.02002.pdf)
Action correction: from coarse to finer-grained predictions
트랜스포머는 multi-modal action을 모델링 하는데 좋지만 continous variable에 대해 모델링 하려면 Discretization이 필연적이다. 하지만 연속 공간을 어떤식으로든 이산화하면, 부정확할 수 밖에 없고 Discretization 오류로 인해 hehavior policy으로 온라인 rollout을 하게되면 원래 데이터의 분포와 다를 수 있고, 이는 critical failure를 가져올 수 있다. 기존의 Decison Transformer, Trajectory Transformer는 모두 continuous task에 대해 discretization을 해주고 bin centor를 output하는 형태를 보였지만 BeT는 여기서 한발 더 나아가 residual action이라는 것을 사용해 complete continous action을 out한다. 이를 위한 추가적인 head를 transformer decoder에 붙이고, observation을 기반으로 discritezed action center를 상쇄하도록 한다.

각 observation o_i에 대해, head는 bin centor A_1, .. A_k에 해당하는 k개의 residual action vector를 생성한다. 이러한 residual action은 object detection에서 사용하는 masked muti-task loss와 유사하다고 하고 식(2)와 같다. masked multi-task loss라고 하는거는 multi-task를 한다는게 아니라, Fast R-CNN에서 classification loss와 regression loss를 합친 것을 의미하는 걸로 보아, token distribution modeling과 residual action regression을 같이 한다 이렇게 보는 게 맞을 것 같다. action bin label이 j인 경우에만 ground truth continuous action a와 예측된 residual a^j에 대한 MSE loss로 보면 된다.
Test-time sampling from BeT

Test time에서 현재 timestep t에서, 현재 observation o_t와 이전 최신의 h-1 observatoin을 합친뒤 transformer에 input하면 model은 h*1*k개의 bin center의 확률 벡터와 h*k*dim(A)의 offset matrix를 아웃한다. 이는 각각 action center와 residual actiono이므로 이 두 값을 더해서 continous action \hat{a_t}로 최종 action을 예측한다.
Discurssion
이 논문에서는 multi-modal demo dataset에서 continuous action model predictor가 있는 Transformer 기반 backbone을 사용해 continuous action sequence를 모델링하는 Behavior Transformer를 소개하였다. BeT는 가능성을 보여주지만, 실세계에서 사람의 demo나 상호작용을 통해 다양한 행동을 학습할 때 사용되는 것이 진정한 의미의 활용이다. 또한 온라인 상호작용 중 BeT로부터 특정 unimodal behavior policy를 추출하거나 적절한 prompt를 생성하면 온라인 RL에서의 Prior로도 유용하게 쓰일 것이라고 한다.
이 논문에서 액션 분포를 mixture of gaussian로 모델링한다고 하는데, 내가 영어를 잘못 해석한 것인지 모르겠지만 트래스포머가 mixture of gaussian을 모델링 해줄 것 같지는 않다. 이 논문의 의의는 transformer를 통해 history conditioned action distribution을 모델링한다는 것이다. 즉 트랜스포머가 모델링하는 behavior policy는, history에 대해 marginalize하면 multi modal distribution이 될 것이고 history에 dependent한 policy를 낼 수 있다는 것이다.
'인공지능 AI' 카테고리의 다른 글
Contents
소중한 공감 감사합니다