인공지능 AI
[RL] Bayes-Adaptive Monte-Carlo Planning and Learning for Goal-Oriented Dialogues
- -
Paper URL : http://ailab.kaist.ac.kr/papers/pdfs/JLK2020.pdf
Abstract
Strategic dialogue task 문제는 Bayesian Planning으로 formuate 될 수 있는데, 모든 발화의 경우의 수를 고려해야하므로 엄청 큰 Search Space 때문에 bayesian planning으로 풀기는 어렵다. 그래서 해당 논문에서는 효율적으로 Bayes-adaptive planning algorithm을 사용해서 goal-oriented dialogue task를 푸는 것을 제안한다. 해당 알고리즘은 줄여서 BADP라고 하고 RNN-based 대화 생성 모델과 MCTS(Monte carlo tree search)-based Bayesian planning을 합친 알고리즘이다. 해당 논문에서 푸는 task는 2 에이전트가 있고 협상을 수행해아 하는 task인데 상대의 goal을 모른다는 uncertainty가 존재하고 이 알고리즘을 이용하면 이런 uncetainty에도 robust 한 decision-making을 할 수 있다.
MCTS를 policy improvement operator로 사용하는데 이는 Alphago와 Alphazero에서 쓰이는 방법과 같다. MCTS를 통해 planning을 해서 Data를 생성하고, MCTS로 찾아진 더 나은 policy를 가진 Data로 Supervised learning을 하는 방법이다.
Introduction
Goal-oriented dialogue task는 2가지 이유로 challenging하다.
1. 다른 agent의 goal을 직접적으로 관찰 할 수 없으므로 agent는 다른 agent의 goal의 uncertainty가 있는 상태에서 planning을 해야 한다. 이런 문제는 Bayesian planning문제로 해결할 수있다고 알려져 있지만 Bayes-optimal policy를 계산하는 것은 작은 문제가 아니라면 불가능하다고 볼 수 있다.
2. goal-oriented dialogue task를 Vanilla RL(e.g. REINFORCE)로 푸는 것은 policy gradient estimator의 high variance로 인해 효율적이지 않고 불안정한 training을 낳는다. 그리고 이는 human language가 낳는 Divergence가 초래되는 문제점이 있다.
Divergence 문제를 해결하기 위해서 MLE training(supevised learning)이 사용됬지만 그래도 여전히 divergence 문제는 존재한다. 그래서 Latent repersentation을 사용하는 방법도 제안 되었지만 gradient update를 위해 REINFORCE 알고리즘을 사용하기 때문에 training이 불안정하고 local optima로 빠지는 경향이 있다.
그래서 해당 논문에서 제안하는 방법은 RNN based의 Dialogue generator와 MCTS based Bayes-optimal planning를 approximate하는 BADP(Bayes-adaptive dialogue planning)알고리즘을 제안한다. Dialgue Generator는 대화 발화를 sampling하고 RNN 레이어를 통해서 이전 발화들(history)를 반영하면서 현재 발화를 sampling한다. 그런 다음 sample된 발화에서 Best를 MCTS를 통해 찾는다. Search동안 다른 Agent의 goal의 posterior distribution을 유지하게 된다. 이렇게 되면 사람 대화 같은 natural을 유지하면서 다른 agent goal의 uncertainty에 robust하게 된다는 장점이 있다. BAMCP(Bayes-adaptive Monte Carlo planning, Cuez, Silver and Dayan 2012;2013) 논문에서 소개한바 있듯이 Bayes-adaptive Monte Carlo planning 알고리즘은 샘플 기반 트리 서치를 사용해서 Bayes planning에서 갖는 curse of dimensionality 문제를 완화하며, 루트 샘플링은 반복적이고 expensive한 posterior 업데이트를 막아준다.
해당 알고리즘에서 MCTS를 plicy improvement operator로 사용하기 때문에(recursive하게 policy를 업데이트) Single-step update(e.g. TD learning) 방법보다 dialogue task 같이 multi-turn task나 credit assignment 문제(현재 선택이 미래에 영향을 받는)에 더 강하다. Policy gradient method들이 local improvement를 하는 반면 , alphago, zero에서 보았듯 self-play를 통해 만들어진 Data를 통해 Supervised learning을 하면 local optima에 빠지지 않고 Global policy improvement가 가능하고 training이 안정적이고 gradient의 variance가 작다는 장점이 있다. 하지만 supervised learning 은 Credit assignment 문제는 풀기 어렵다는 단점이 있다.
간단하게 말하면 해당 논문은 AlphaZero 에서 사용한 방법을 Dialogue task에 맞게 바꾸어 적용한 것이라고 볼 수있다.
Background
여기서 실험에 사용하는 task는 협상 Dialogue task로 두 에이전트가 있고 3가지의 Item이 있고 각각 Item의 가격을 goal로 갖고 있다. goal은 0에서 10 사이의 정수이고 랜덤하게 할당되며 상대 에이전트의 goal을 알 수 없다. 협상이 되면 에피소드는 끝나고 각 에이전트는 동등한 리워드를 받고 협상이 이루어지지 않으면 0의 리워드를 받는다.
이런 종류의 Goal-oriented Dialog는 여러 도전 과제가 있지만 여기서 집중한 문제는,
- Bayes-optimal planning: 에이전트는 상대의 goal을 볼 수 없으므로 상대 goal의 Posterior를 고려해서 Bayes-optimal solution을 찾아야 한다.
- Stable RL: REINFORCE 알고리즘은 큰 variance 때문에 불안정하고 divergence문제가 있으므로 stable한 RL 알고리즘을 사용한다.
Bayes-adaptive Monte-Carlo Planning
Dialogue task에 Bayes-adaptive Monte-Carlo Planning를 적용한 fomulate한 recursive Bellman's Equation은 아래 식과 같다.

여기서 P(g_y|h)는 상대 골의 Posterior distribution이고 R(h,x)는 대화 히스토리 h와 현재 발화 x가 주어졌을 때 받는 리워드이고, P(h|h,x,g_y)는 Dialogue Generator모델이다. 위 재귀 벨만 방정식은 작은 문제에서만 적용이 가능하므로 Alpha Zero에서 처럼 Non-uniform search를 통해 좋은 node를 선택하고 root sampling에서 posterior update를 하지 않아야 한다.
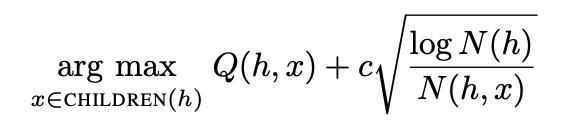
BAMCP에서는 environment model P를 posterior 분포 P(P|h)를 통해 샘플하고, MCTS 종류 중 하나인 UCB를 이용해서 action을 select한다. UCB는 exploration term을 Visit count를 통해 제한하는 간단하면서 optimal 솔루션으로 잘 알려져 있어 MCTS에서 가장 많이 사용되는 method이다. Q(h,x)는 h에서 선택된 action x가 선택될 때 샘플된 reward의 평균 Value이며 N(h)는 node h의 simulation수, N(h,x)는 node h에서 action x가 선택된 횟수, c는 exploration constant이다.
Progressive Widening
Dialogue task 에서 action은 모든 가능한 발화이며 그 cardinality는 infinte이다. 그래서 classic UCT를 바로 적용할 수 없고 Progressive Widening을 사용해야 한다. Progressive Widening은 가능한 action수를 finite로 제한한다.

노드 h에서 가능한 액션의 수가 노드 h의 visit count의 알파승을 넘을 수 없게 제한한다.
Model Component
BADP는 Text generation model과 Action selection model로 이루어져 있다.
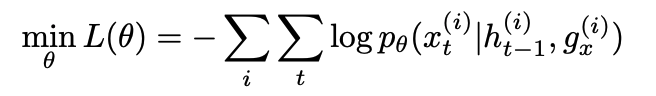
Text Generation model은 attention based RNN 모델이고 모델은 NLL(negative log likelihood) loss로 트레이닝 되고, history와 Agent goal이 주어지면 다음 utterance를 predict한다.
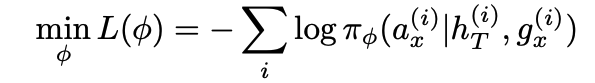
Action selection model은 Policy model이라고 보면 된다. 마지막 history 즉 전체 history와 goal이 주어지면 action을 내놓는다. 여기서 superscript i는 데이터셋의 episode를 의미한다. 해당 모델은 utterance-level 이기 때문에 전체 히스토리당 1개의 action을 셀렉한다. Action selection model 즉 policy model도 attention based의 RNN 모델이다. Text generation 모델과 비슷학 NLL loss를 통해 learning된다. 즉 planning(MCTS search)를 통해 나온 데이터 셋을 가지고 Action selection model을 learning한다.
Posterior Inference

상대 agent gaol을 g_y라고 하고 Generator model P_theta와 uniform categorical 분포인 Prior P(g_y)를 통해 샘플한다.
Overall Algorithm


1. root node에서 상대 골 g_y를 Posterior에서 샘플하고 샘플된 g_y 로 Simulation한다.
2. Progressive widening을 만족하면 새로운 노드를 Generator p_theta에서 new utterance를 샘플하고 tree에 expand한다.
3. Rollout동안 Next sentence x_t+1을 UCT를 통해 Select하거나 Generator p_theta를 통해 샘플링한다.
4. Dialogue simulation이 끝나면 최종 리워드를 Root node까지 Backpropagate한다.
Policy Improvement via Bayes-Adaptive Dialogue Planning


AlphaZero와 비슷하게 BADP알고리즘을 통해 Self-play해서 생성된 데이터(using pi(Action selection model), Text Generator trained SL)는 이전 데이터보다 더 좋은 리워드를 가지게 된다. 이렇게 생성된 데이터를 Policy improvement에 이용하며 Supervised learning을 통해 Exploit된다. 그리고 이 과정을 Policy가 수렴할때까지 반복한다.
'인공지능 AI' 카테고리의 다른 글
| [RL] Efficient Planning in a Compact Latent Action Space, TAP (0) | 2023.03.19 |
|---|---|
| [CS25 1강] Transformers United: DL Models that have revolutionized NLP, CV, RL (0) | 2023.03.15 |
| KL-Divergence (1) | 2022.03.20 |
| Model-based Reinforcement Learning (0) | 2022.03.18 |
| MLE(Maximum Likelihood Estimation) 최대우도법 (0) | 2021.10.28 |
Contents
소중한 공감 감사합니다